最近又收到了运维报警:表示有些服务器负载非常高,让我们定位问题。

还真是想什么来什么,前些天还故意把某些服务器的负载提高(没错,老板让我写个Bug!),不过还好是不同的环境,互相没有影响。
定位问题
拿到问题后首先去服务器上看了看,发现运行的只有我们的Java应用。于是先用PS命令拿到了应用的PID。
接着使用top-Hppid将这个进程的线程显示出来。输入大写的P可以将线程按照CPU使用比例排序,于是得到以下结果:
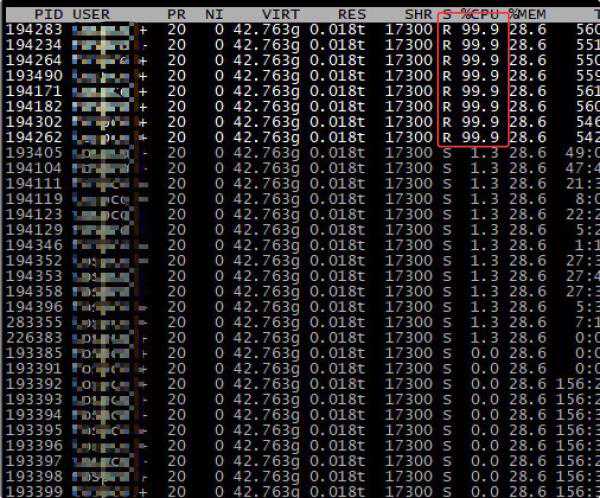
果然某些线程的CPU使用率非常高。为了方便定位问题我立马使用将线程栈Dump到日志文件中。
我在上面100%的线程中随机选了一个pid=194283转换为16进制(2f6eb)后在线程快照中查询,因为线程快照中线程ID都是16进制存放。

发现这是Disruptor的一个堆栈,前段时间正好解决过一个由于Disruptor队列引起的一次OOM,没想到又来一出。
为了更加直观的查看线程的状态信息,我将快照信息上传到专门分析的平台上:
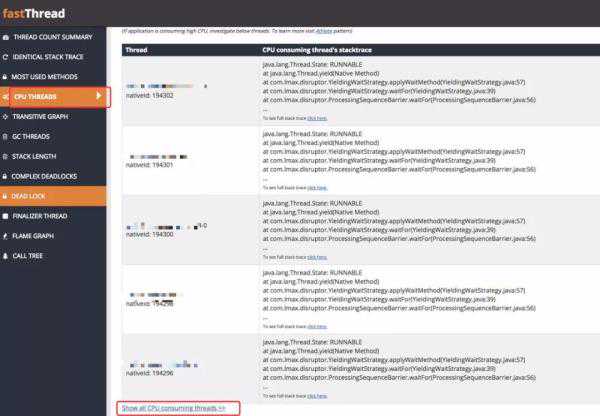
其中有一项菜单展示了所有消耗CPU的线程,我仔细看了下发现几乎都是和上面的堆栈一样。
也就是说都是Disruptor队列的堆栈,同时都在执行函数。
众所周知yield函数会让当前线程让出CPU资源,再让其他线程来竞争。
根据刚才的线程快照发现处于Runnable状态并且都在执行yield函数的线程大概有30几个。
因此初步判断为大量线程执行yield函数之后互相竞争导致CPU使用率增高,而通过对堆栈发现是和使用Disruptor有关。
解决问题
而后我查看了代码,发现是根据每一个业务场景在内部都会使用2个Disruptor队列来解耦。
假设现在有7个业务类型,那就等于是创建2*7=14个Disruptor队列,同时每个队列有一个消费者,也就是总共有14个消费者(生产环境更多)。
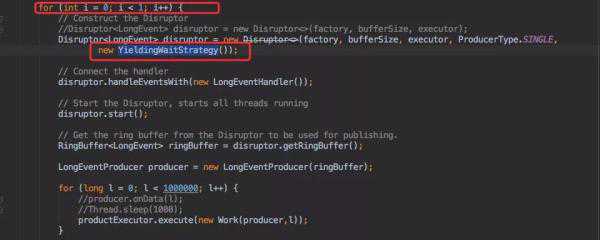
同时发现配置的消费等待策略为YieldingWaitStrategy这种等待策略确实会执行yield来让出CPU。
代码如下:
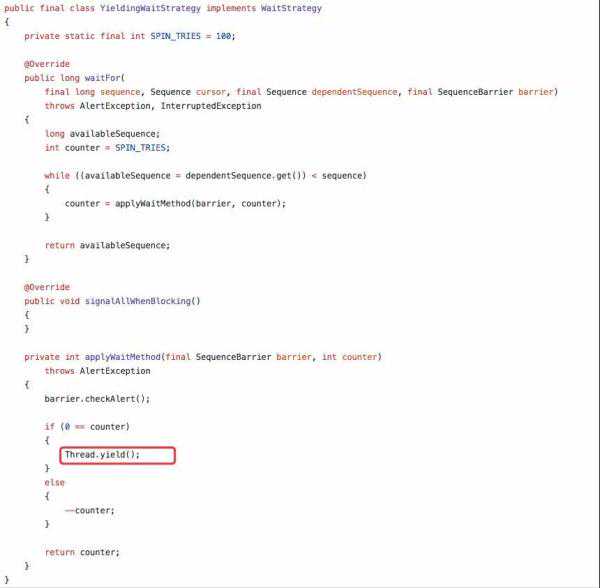
初步看来和这个等待策略有很大的关系。
本地模拟
为了验证,我在本地创建了15个Disruptor队列同时结合监控观察CPU的使用情况。
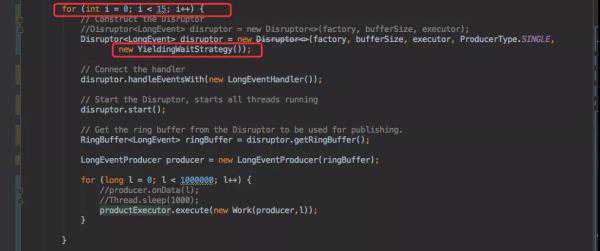

创建了15个Disruptor队列,同时每个队列都用线程池来往Disruptor队列里面发送100W条数据。
消费程序仅仅只是打印一下:
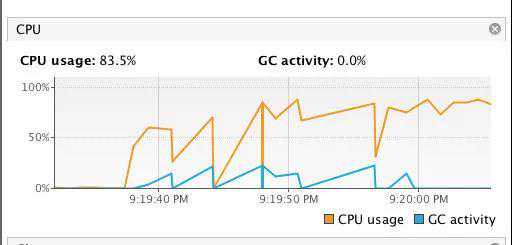
跑了一段时间发现CPU使用率确实很高:
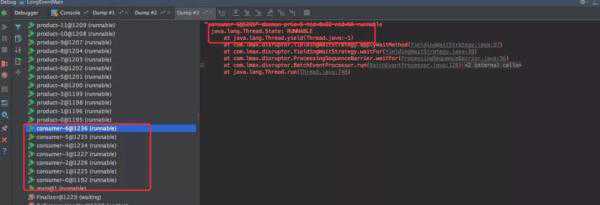
同时Dump线程发现和生产的现象也是一致的:消费线程都处于Runnable状态,同时都在执行yield。
通过查询Disruptor官方文档发现:

YieldingWaitStrategy是一种充分压榨CPU的策略,使用自旋+yield的方式来提高性能。
当消费线程(EventHandlerthreads)的数量小于CPU核心数时推荐使用该策略。

同时查阅到其他的等待策略BlockingWaitStrategy(也是默认的策略),它使用的是锁的机制,对CPU的使用率不高。
于是在和之前同样的条件下将等待策略换为BlockingWaitStrategy。

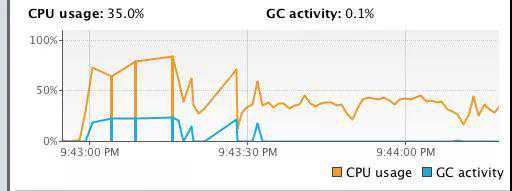
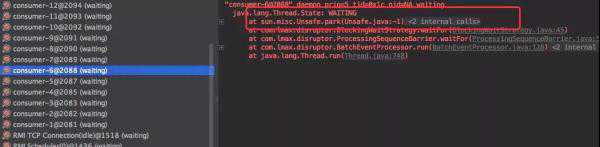
和刚才的CPU对比会发现到后面使用率会有明显的降低;同时Dump线程后会发现大部分线程都处于Waiting状态。
优化解决
看样子将等待策略换为BlockingWaitStrategy可以减缓CPU的使用。
但留意到官方对YieldingWaitStrategy的描述里谈到:当消费线程(EventHandlerthreads)的数量小于CPU核心数时推荐使用该策略。
而现有的使用场景很明显消费线程数已经大大的超过了核心CPU数了,因为我的使用方式是一个Disruptor队列一个消费者,所以我将队列调整为只有1个再试试(策略依然是YieldingWaitStrategy)。
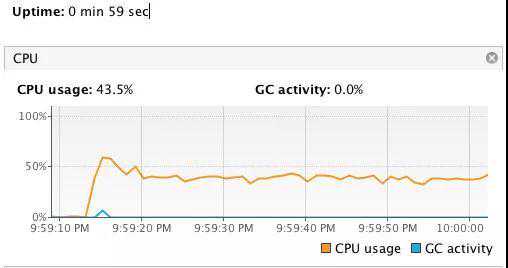
跑了一分钟,发现CPU的使用率一直都比较平稳而且不高。
总结
所以排查到此可以有一个结论了,想要根本解决这个问题需要将我们现有的业务拆分;现在是一个应用里同时处理了N个业务,每个业务都会使用好几个Disruptor队列。
由于是在一台服务器上运行,所以CPU资源都是共享的,这就会导致CPU的使用率居高不下。
所以我们的调整方式如下:
为了快速缓解这个问题,先将等待策略换为BlockingWaitStrategy,可以有效降低CPU的使用率(业务上也还能接受)。
第二步就需要将应用拆分(上文模拟的一个Disruptor队列),一个应用处理一种业务类型;然后分别单独部署,这样也可以互相隔离互不影响。
当然还有其他的一些优化,因为这也是一个老系统了,这次Dump线程居然发现创建了800+的线程。
创建线程池的方式也是核心线程数、最大线程数是一样的,导致一些空闲的线程也得不到回收;这样会有很多无意义的资源消耗。
所以也会结合业务将创建线程池的方式调整一下,将线程数降下来,尽量的物尽其用。
作者:crossoverJie



