本期的智能内参,我们推荐清华AMiner的报告《人工智能发展月报》,跟踪最新的人工智能发展动态。
《人工智能发展月报》
一、AI顶会与奖项1、2022世界移动通信大会在西班牙召开中国移动、中国联通、中国电信中国三大运营商负责人集体以线上方式亮相大会主旨演讲,中国移动表示计划到今年底累计开通5G基站超百万个,推动5G网络客户规模超3.3亿户,打造5G商用案例超万个;中国电信表示,率先实现了云、网络、IT(信息技术)的统一运营,不断推进云网融合,已经取得初步成效;中国联通助力北京打造了“第一届真正意义上的5G冬奥会”。
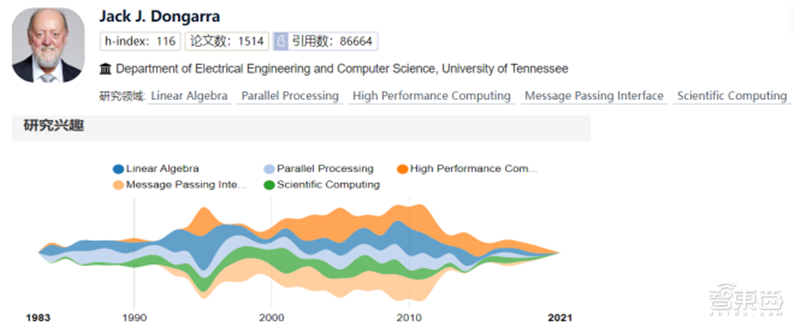
2、CVPR2022论文接收量比去年上升24%3、图灵奖授予高性能计算领域先驱JackDongarra3月30日,美国计算机协会(ACM)将2021年的图灵奖授予美国田纳西大学电气工程和计算机科学系特聘教授、现年71岁的,表彰他在数值算法和工具库方面的开创性贡献,使高性能计算软件能够跟上四十多年来的指数级硬件改进。据ACM介绍,Dongarra的算法和软件推动了高性能计算发展,并对从人工智能到计算机图形学的多个计算科学领域产生了重大影响。
4、全美计算机研究生院排名:MIT、CMU分别称霸总榜和AI分榜
3月29日,2023全美研究生院排名正式发布。最佳计算机科学研究生院排名5名分别为,第1名麻省理工学院(MIT)、并列第2的卡内基·梅隆大学(CMU)、斯坦福大学和加利福尼亚大学伯克利分校(UCB),以及第5名伊利诺伊大学厄巴纳-香槟分校(UIUC)。
在人工智能专业上,排名第一是卡内基·梅隆大学(CMU)。

全美人工智能专业排名
5、智谱榜单:人工智能全球女性学者美国占比超6成,中国23人入围近日,2022年“人工智能相关领域全球女性学者”名单公布,入围人数共262人,分布在全球19个国家。从国别分布看,美国共入围161人,占比61.5%;其次是中国(含港澳台地区),共有23人,占8.8%;第三是英国,共有14人;从机构分布看,全球前十强机构中,美国占8家,谷歌排名全球第一,中国和法国各占1家,清华大学是我国唯一一家进入前十强的机构;从研究领域分布看,排名依次是人机交互(51人次)、可视化(24人次)、知识工程(22人次)、机器学习(6人次)、机器人(6人次)和计算机系统(7人次);在262人中,共有71位华人,占比达27.1%,而71位华人中,23位工作单位在中国,48位工作单位在外国。
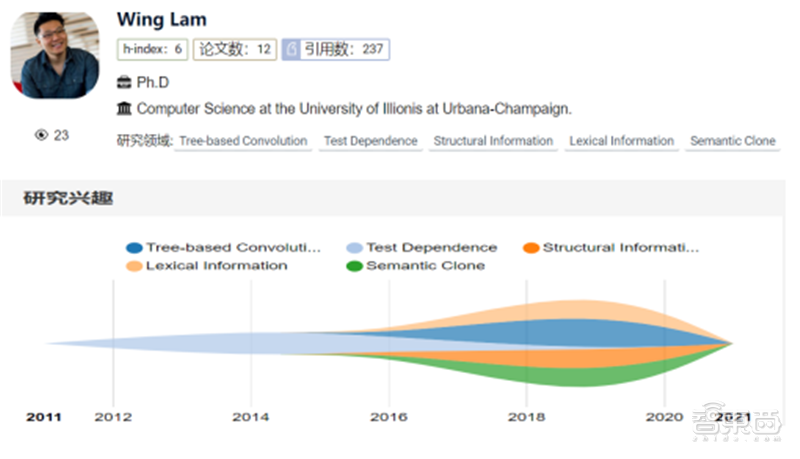
6、华人博士获ACMSIGSOFT杰出博士论文奖2022ACMSIGSOFTOutstandingDoctoralDissertationAward(杰出博士论文奖)已公布,唯一的名额授予了美国UIUC大学的华人博士生WingLam(林永政),以表彰他在软件工程方面所做出的杰出贡献。
7、2022苹果博士奖学金名单:浙大一博士生入选
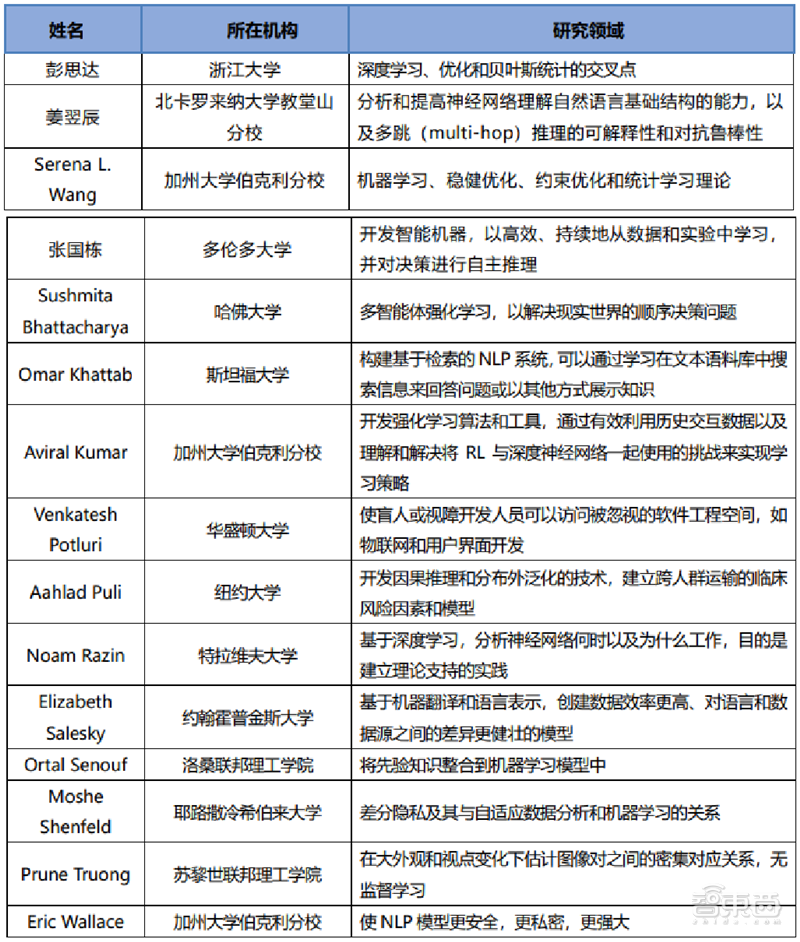
近日,苹果宣布了2022年人工智能/机器学习领域的博士生奖学金名单,共有15位学生入选,包括4位华人博士生,其中一位是来自浙江大学计算机科学专业的彭思达,师从周晓巍教授。
二、AI人才动态1、寒武纪副总经理兼首席技术官梁军已离职
3月14日,寒武纪公告称:原副总经理、首席技术官梁军因与公司存在分歧,已于2月10日通知公司解除劳动合同,目前已办理完离职手续,此后将不再担任公司的任何职务。梁军自2017年加入公司,任职期间曾参与研究并申请发明专利138项、PCT10项,均为非单一发明人。其中14项发明专利已授权,其余仍处于审查阶段。
2、英特尔图形部门顶级专家MikeBurrows跳槽AMD曾担任英特尔专注游戏和图形技术的AdvancedTechnologiesGroup的负责人、首席技术官和总监MikeBurrows,近日宣布以公司副总裁的身份加入AMD团队,领导其高级图形项目。在AMD,Burrows将专注于实时光线追踪和机器学习领域的研究。此外,他还将涉及包括与图形和计算解决方案的缩放相关的技术,以及数据压缩类技术。
3、滴滴实验室(洛杉矶)首席科学家KevinKnight离职近日,原任滴滴实验室(洛杉矶)自然语言处理组首席科学家的NLP大神KevinKnight宣布将从滴滴实验室离职。此外,KevinKnight还是南加州大学(USC)计算机科学系院长教授以及ACL2011的大会主席,2014年同年入选ACLFellow、AAAIFellow,他的学术成果颇多,研究方向涵盖人工智能、自然语言处理、机器翻译、对话处理等。
4、前百度Apollo平台研发总经理王京傲加盟自动驾驶初创公司前百度副总裁、Apollo平台研发总经理王京傲,加盟自动驾驶初创公司云骥智行,担任联合创始人及CTO。王京傲本科毕业于北京大学,于美国辛辛那提大学获得计算机工程硕士学位后,又在加州大学伯克利分校取得MBA学位,目前拥有60多项中美专利。他曾负责百度的自动驾驶Apollo开放平台的整体研发、规划和运营,并主导Apollo平台1.0到7.0所有版本的开发和迭代;之前,曾任职谷歌,是安卓1.0初创团队成员之一。云骥智行成立于2021年11月。在今年的GTC2022大会上,云骥智行宣布将与英伟达合作,在自动驾驶芯片(DRIVEOrinSoC)上搭载云骥智行最新的L4级自动驾驶计算平台。
三、各AI子领域重要科研进展1、机器学习牛津大学:研究者提出了受物理启发的持续学习模型,从微分几何、代数拓扑和微分方程等领域出发开启了一系列新工具的研究,可以克服传统GNN的局限性。
微软、斯坦福大学:就过度参数化(overparameterization)现象,研究者认为比预期规模更大的神经网络是必要的,通过提出平滑性,来指出需要多少个参数才能用一条具有等同于鲁棒性的数学特性的曲线来拟合数据点。论文标题:AUniversalLawofRobustnessviaIsoperimetry论文链接:
上海交通大学、Mila魁北克人工智能研究所、字节跳动:提出了一种基于层级语义结构的选择性对比学习框架(HiearchicalContrastiveSelectiveCoding,HCSC),通过将图像表征进行层级聚类,构造具有层级结构的原型向量(hierarchicalprototypes),并通过这些原型向量选择更加符合语义结构的负样本进行对比学习,由此将层级化的语义信息融入到图像表征中,在多个下游任务中达到卷积神经网络自监督预训练方法的SOTA性能。
论文标题:HCSC:HierarchicalContrastiveSelectiveCoding论文链接:
斯坦福大学:研究了在预训练文本具有远程连贯性的数学设置下,预训练分布对上下文学习的实现所起的作用,证明了当预训练分布是混合隐马尔可夫模型时,上下文学习是通过对潜在概念进行贝叶斯推理隐式地产生的,生成了一系列小规模合成数据集(GINC),在这个过程中,Transformer和LSTM语言模型都使用了上下文学习。论文标题:AnExplanationofIn-ContextLearningasImplicitBayesianInference
阿里巴巴:提出了一个叫做猎豹(Cheetah)的新型框架,用于深度神经网络的两方计算网络推理系统,并重新设计了基于同态加密的协议,可在不需要任何轮调操作(RotationOperation)的情况下评估线性层(即卷积、批量归一化和完全连接);设计了几个用于非线性函数(如ReLU和Truncation)的更加精简,通信效率更高的基元。
德国希尔德斯海姆大学:评估了特征工程多输出GBRT模型,该研究将一个简单的机器学习方法GBRT提升了竞品DNN时间序列预测模型的标准;实证了为什么基于窗口的GBRT输入设置可以在时间序列预测领域提高ARIMA和原版GBRT等精心配置的模型所产生的预测性能;比较了GBRT与各种SOTA深度学习时间序列预测模型的性能,并验证了它在单变量和双变量时间序列预测任务中的竞争力。
论文标题:DoWeReallyNeedDeepLearningModelsforTimeSeriesForecasting?论文链接:
中国科学技术大学:针对移动为中心的模型推理场景,提出端到端可学的输入过滤框架InFi(INputFIlter),对输入过滤问题进行了形式化建模,并基于推理模型和输入过滤器的函数族复杂性对比,在理论层面上对推理任务的可过滤性进行分析,InFi框架涵盖了现有的SOTA方法所使用的推理跳过和推理重用机制。
论文标题:InFi:-to-LearnableInputFilterforResource-efficientMobilecentricInference
清华大学:针对无监督时序异常检测问题,提出了基于关联差异的异常检测模型Anomalytransformer,并通过一个极小极大(Minimax)关联学习策略大幅提高了模型的异常检测能力。该模型在服务器监测、地空探索、水流观测等应用中均展现出优秀的异常检测结果,应用落地价值强。论文标题:AnomalyTransformer:TimeSeriesAnomalyDetectionwithAssociationDiscrepancy
清华大学:模仿海马体的神经元权重更新机制,在NatureCommunications上提出了一种结合全局与局部权重更新规则的混合模型,并验证了该模型在高噪声、小数据量、持续学习三种任务场景下的优越性,为神经形态算法及其硬件实现的协同开发开辟了一条新的路径。论文标题:Brain-inspiredglobal-locallearningincorporatedwithneuromorphiccomputing
瑞士托埃尔特公司:TOELTLLC联合创始人兼首席AI科学家UmbertoMichelucci全面介绍了自编码器的由来、定义、由编码器、潜在特征表示和解码器三部分组成,并详细介绍了编码器和解编码器。
论文标题:AnIntroductiontoAutoencoders论文链接:
清华大学、旷视科技等:通过一系列探索实验,总结了在现代CNN中应用超大卷积核的五条准则,并基于以上准则,借鉴SwinTransformer宏观架构,提出了一种RepLKNet架构。
论文标题:ScalingUpYourKernelsto31×31:RevisitingLargeKernelDesigninCNNs论文链接:
布朗大学:该论文提出了强化学习中蕴含的抽象理论,指出执行抽象过程的函数所必备的三要素:维护近似最优行为的表示、它们应该被有效地学习和构建;计划或学习时间不应该太长。然后提出了一套新的算法和分析方案,阐明智能体如何根据这些要素学会抽象。论文标题:ATheoryofAbstractioninReinforcementLearning论文链接:
微软、OpenAI:首次提出了基础研究如何调优大型神经网络(这些神经网络过于庞大而无法多次训练),通过展示特定参数化保留不同模型大小的最佳超参数来实现,利用µP将HP从小型模型迁移到大型模型。并在Transformer和ResNet上验证µTransfer。结果表明,1)该研究优于BERTlarge(350M参数),总调优成本相当于一次预训练BERT-large;2)通过从40M参数迁移,该研究的性能优于已公开的6.7BGPT-3模型,调优成本仅为总预训练成本的7%。
论文标题:TensorProgramsV:TuningLargeNeuralNetworksviaZero-ShotHyperparameterTransfer论文链接:
北京大学、清华大学:下游任务可以从预训练模型中继承容易受攻击的权重。研究者提出一个名叫ReMoS的方法,有选择性地筛选出那些对下游任务有用且不易受攻击的权重,在最多损失3%精度的前提下,使得微调后的模型受攻击率大大减小:CV(ResNet)任务上受攻击率减小了63%到86%,NLP(BERT、RoBERTa)任务上则减小了40%到61%。
谷歌:提出了一种在有偏见的数据上使用GNN的解决方案Shift-RobustGNN(SR-GNN)。这个方法的目的就是要让问题域发生变化和迁移时,模型依然保持高稳健性,降低性能下降。实验表明,SR-GNN在准确性上优于其他GNN基准,将有偏见的训练数据的负面影响减少了30-40%。
论文标题:Shift-RobustGNNs:OvercomingtheLimitationsofLocalizedGraphTrainingdata论文链接:
港科大、星云Clustar:香港科大智能网络与系统实验室iSINGLab和国内隐私计算算力提供商星云Clustar合作,提出了一种隐私保护在线机器学习场景下的新框架Sphinx。Sphinx结合同态加密、差分隐私和秘密共享多种隐私保护技术,根据训练和推理的具体任务特点提出了定制且兼容的训练和推理混合协议,从而实现快速的训练和推理计算。速度提升达4-6个数量级。该论文已被IEEE安全与隐私研讨会(IEEESP“Oakland”)收录。论文题目:Sphinx:EnablingPrivacy-PreservingOnlineLearningovertheCloud
2、计算机视觉谷歌研究院、哈佛大学:提出了mip-NeRF的扩展模型,它使用非线性场景参数化、在线蒸馏和新颖的基于失真的正则化器来克服无界场景带来的挑战,该模型被称为「mip-NeRF360」,因为该研究针对的是相机围绕一个点旋转360度的场景,与mip-NeRF相比,均方误差降低了54%,并且能够生成逼真的合成视图和详细的深度用于高度复杂、无界的现实世界场景的地图。
论文标题:Mip-NeRF360:UnboundedAnti-AliasedNeuralRadianceFields论文链接:
论文标题:CraftingBetterContrastiveViewsforSiameseRepresentationLearning论文链接:
Adobe、中佛罗里达大学:开发了在StyleGAN生成的图像中,用于保护身份的多重面部属性编辑的学习映射器。该研究使用一个神经网络来执行潜意识到潜意识的转换,找到与属性改变的图像相对应的潜编码,通过在整个生成pipeline上端对端训练网络,该系统可以适应现有的生成器架构的潜空间,并能够保护属性(Conservationproperties),一旦latent-to-latent网络训练完,就可以用于任意的图像输入,而不需要微调。论文标题:LatenttoLatent–ALearnedMapperforIdentityPreservingEditingofMultipleFaceAttributesinStyleGAN-generatedImages
字节跳动AML团队:基于PyTorch框架,以Megatron和DeepSpeed为基础,该研究团队开发了火山引擎大模型训练框架veGiantModel。现已在GitHub上开源,地址如下:
复旦大学:复旦大学数据智能与社会计算实验室提出了一种基于多层次语义对齐的多阶段视觉–语言预训练模型MVPTR。MVPTR通过显式地学习表示不同层级的,来自图片和文本信息的语义,并且在不同的阶段对齐不同层次的语义,在大规模图片–文本对语料库上预训练的MVPTR模型在下游视觉–语言任务上取得了明显的进展,包括图片-文本检索、视觉语言问答、视觉推断、短语指代表示。
论文标题:MVPTR:Multi-StageVision-LanguagePreTrainingviaMulti-LevelSemanticAlignment
中国人民大学:中国人民大学GeWu实验室以判别性声源定位为基础实现了构建物体类别认知的目标,并将其应用在其他经典视觉任务中。该研究提出了判别性多声源定位任务,以及两阶段的学习框架。还通过解决判别性声源定位任务构建对不同类别物体视觉表征的认知,并将其迁移到其他经典视觉任务中,如物体检测等。
论文标题:Class-awareSoundingObjectsLocalizationviaAudiovisualCorrespondence
MetaAI:宣传其自监督模型SEER(SElf-supERvised)突破至100亿参数,并取得更优秀、更公平的性能表现。该模型不仅在ImageNet上取得了高达85.8%的准确率(排名第一),与原先只有10亿参数量的SEER(84.2%)相比性能提升了1.6%。此外,在性别、肤色、年龄等三个公平基准上获得了更出色的识别效果,明显优于监督模型。
论文标题:VisionModelsAreMoreRobustAndFairWhenPretrainedOnUncuratedImagesWithoutSupervision
苏黎世联邦理工学院:开发了名为Pix2NeRF的AI,可以在没有3D数据、多视角或相机参数的情况下学会生成新视角。Pix2NeRF包含生成网络G、判别网络D和编码器E三种类型的网络架构。
康奈尔大学、谷歌大脑:提出了一个新模型FLASH(FastLinearAttentionwithaSingleHead),首次不仅在质量上与完全增强的Transformer相当,而且在现代加速器的上下文大小上真正享有线性可扩展性,并且训练成本只有原来的1/2。
论文标题:TransformerQualityinLinearTime论文链接:
清华大学、南开大学:研究者提出了一种新型大核注意力(largekernelattention,LKA)模块,克服现存问题的同时实现了自注意力中的自适应和长距离相关性,还进一步提出了一种基于LKA的新型神经网络,命名为视觉注意力网络(VAN)。在图像分类、目标检测、语义分割、实例分割等广泛的实验中,VAN的性能优于SOTA视觉transformer和卷积神经网络。
论文标题:VisualAttentionNetwork
华为诺亚方舟实验室、北京大学、悉尼大学:提出了一种受量子力学启发的视觉MLP架构,在ImageNet分类、COCO检测、ADE20K分割等多个任务上取得了SOTA性能。论文标题:AnImagePatchisaWave:QuantumInspiredVisionMLP论文链接:
加州大学圣圣地亚哥分校、英伟达:通过对具有对比损失的大规模配对图文数据进行训练,可以让模型不需要任何进一步的注释或微调的情况下,能够零样本迁移学习得到未知图像的语义分割词汇。
论文标题:GroupViT:SemanticSegmentationEmergesfromTextSupervision
北大、字节跳动:利用域自适应思想,提出新框架显著增强基于图像级标签的弱监督图像定位性能。
论文标题:WeaklySupervisedObjectLocalizationasDomainAdaption
谷歌、MIT、DeepMind、MILA和剑桥大学等:基于跨平台开源物理引擎PyBullet和3D图像渲染软件Bler打造了一个名叫Kubric的数据集生成器,能一键生成各种图像数据包括语义分割、深度图或光流图这种“特殊数据”,还能控制渲染的真实度,达到以假乱真的效果。
华东师范大学:该大学田博博研究员、彭晖教授和段纯刚教授团队实现了基于光生伏特效应的自供电光电传感器的传感内储备池计算。在基于该自供电传感器阵列的传感内储备池计算视觉系统中成功演示了静态人脸图像分类和动态车流方向判别的视觉信息处理任务,分别达到99.97%和100%识别率。
论文标题:Ultralow-PowerMachineVisionwithSelfPoweredSensorReservoir
微软亚研院:利用BERT中MLM(MaskedLanguageModeling)的思路,把一个图像转换成token序列,对图像token进行mask,然后预测被mask掉的图像token,实现图像领域的无监督预训练。
论文标题:BEIT:BERTPre-TrainingofImageTransformers
美图影像研究院、北京航空航天大学:提出分布感知式单阶段模型,用于解决极具挑战性的多人3D人体姿态估计问题。该方法通过一次网络前向推理同时获取3D空间中人体位置信息以及相对应的关键点信息,从而简化了预测流程,提高了效率。此外,还有效地学习了人体关键点的真实分布,进而提升了基于回归框架的精度。
论文标题:Distribution-AwareSingle-StageModelsforMulti-Person3DPoseEstimation论文链接:
Adobe研究院、阿卜杜拉国王科技大学:提出了一种结合多个预训练的GAN进行图像生成的新方法——InsetGAN,共分为两类:1)全身GAN(Full-BodyGAN),基于中等质量的数据进行训练并生成一个人体;2)部分GAN,其中包含了多个针对脸部、手、脚等特定部位进行训练的GAN。
论文标题:InsetGANforFull-BodyImageGeneration
北大、字节跳动:利用域自适应思想,北大、字节跳动提出新型弱监督物体定位框架。将基于CAM的弱监督物体定位过程看作是一个特殊的域自适应任务,使得仅依据图像标签训练的模型可以更为精准的定位目标物体。
论文标题:WeaklySupervisedObjectLocalizationasDomainAdaption
加州大学圣圣地亚哥分校、英伟达:利用视觉Transformer(ViT)中加入新的视觉分组模块GroupViT(分组视觉Transformer)的思想,研究者提出将分组机制加入深度网络。只要通过文本监督学习,分组机
制就可以自动生成语义片段,通过对具有对比损失的大规模配对图文数据进行训练,可以让模型不需要任何进一步的注释或微调的情况下,能够零样本迁移学习得到未知图像的语义分割词汇。
论文标题:GroupViT:SemanticSegmentationEmergesfromTextSupervision
韩东国际大学:研究者提出了单样本(one-shot)超高分辨率(UHR)图像合成框架OUR-GAN,能够从单个训练图像生成具有4K甚至更高分辨率的非重复图像。
论文标题:OUR-GAN:One-shotUltra-high-ResolutionGenerativeAdversarialNetworks
华南理工:提出了一种即插即用融合模块:双跨视角空间注意力机制(VISTA),以产生融合良好的多视角特征,以提高3D目标检测器的性能,使用VISTA卷积算子代替了MLP,能够更好地处理注意力建模的局部线索。将VISTA中的回归和分类任务解耦,以利用单独的注意力建模来平衡这两个任务的学习。可用于各种先进的目标分配策略。
论文标题:VISTA:Boosting3DObjectDetectionviaDualCross-VIewSpaTialAttention
字节跳动:开发了最新的text2image模型,并且效果比VQGANCLIP要真实,尤其是泛化能力还比不少用大量文本-图像数据对训练出来的模型要好很多。
论文标题:CLIP-GEN:Language-FreeTrainingofaTextto-ImageGeneratorwithCLIP
谷歌、MetaAI:提出了一种称为“模型汤”(ModelSoup)的概念,通过在大型预训练模型下使用不同的超参数配置进行微调,然后再把权重取平均。实验结果证明这种方法能够提升模型的准确率和稳健性。
论文标题:Modelsoups:averagingweightsofmultiplefine-tunedmodelsimprovesaccuracywithoutincreasinginferencetime
康奈尔大学、MetaAI:通过Prompt来调整基于Transformer的视觉模型,结果发现:比起全面微调,Prompt性能提升显著。无论模型的规模和训练数据怎么变,24种情况中有20种都完全胜出。
论文标题:VisualPromptTuning
英伟达:NVIDIA在自家GTC2022上发布Omniverse平台新功能,让开发者能够更轻松地开展协作、在全新游戏开发流程中部署AI、为角色制作面部表情的动画。
Unity:3D制作和运营平台Unity震撼首发新一代超现实人类,以4K分辨率实时渲染,让数字人的眼睛、头发、皮肤等细节看起来与真人无异。
3、自然语言处理清华大学、达摩研究院,浙江实验室,北京人工智能研究院:提出了首个基于国产超算的百万亿参数超大预训练模型训练系统BaGuaLu。该系统拥有可以以超过1EFLOPS的混合精度性能训练十万亿参数的模型,并且支持训练高达百万亿规模参数量模型的训练(174T),并且在并行策略、参数存储、数据精度、负载均衡四个方面进行了创新。
论文标题:BaGuaLu:TargetingBrainScalePretrainedModelswithover37MillionCores
哈工大、腾讯AILab:开发了一个预训练模型WordBERT。它包含两个组件:词向量(wordembedding)和Transformer层,WordBERT采用多层双向Transformer来学习语境表示,通过不同的词汇表规模、初始化配置和不同语言,研究人员一共训练出四个版本的WordBERT。
论文标题:PretrainingwithoutWordpieces:LearningOveraVocabularyofMillionsofWords
论文标题:-to-ReferringVideoObjectSegmentationwithMultimodalTransformers
微软亚洲研究院:研究者将Transformer扩展至1000层的同时还保证其稳定性。开发者残差连接处引入了一个新的归一化函数DeepNorm,将Post-LN的良好性能和Pre-LN的稳定训练高效结合了起来,最终将Transformer扩展到2500个注意力和前馈网络子层(即1000层)比以前的模型深度高出一个数量级,将DeepNorm方法应用到Transformer的每一个子层中,就得到了一个全新的DeepNet模型。
论文标题:DeepNet:ScalingTransformersto1,000Layers
DeepMind:发布了新的模型GopherCite,使用根据人类偏好的强化学习(RLHP,reinforcementlearningfromhumanpreferences)训练了一个可以用于开放式问答的模型。解决了语言模型幻觉的问题,通过利用网络上的证据来支持其所有的事实描述。训练结果显示,该模型在自然问题数据集、ELI5数据集上的正确率分别可以达到90%、80%,接近人类水平。
谷歌:为了解决模型在理解表格时总是通过行列顺序的线索作弊的问题,提出了TableFormer,一种对表格行列顺序扰动严格鲁棒的架构,引入了13种可学习的注意力偏置标量。TableFormer还能够更好地编码表格结构,以及对齐表格和相应的文本描述(例如自动问答中的问题)。
论文标题:TableFormer:RobustTransformerModelingforTable-TextEncoding
卡内基梅隆大学:研究团队对PolyCoder、开源模型和Codex的训练和测试设置进行对比研究。使用HumanEval基准研究各种模型大小、训练步骤,以及不同的温度对模型生成代码质量的影响。还创建了一个12种语言的测试数据集,用来评估各种模型的性能。
论文标题:ASystematicEvaluationofLargeLanguageModelsofCode
香港大学、华为诺亚方舟实验室:针对现有大规模生成式预训练语言模型的压缩需求,提出了新的量化压缩解决方案,分别在GPT-2与BART上实现了14.4倍与13.4倍的压缩率,并将量化的GPT模型与BART模型分别命名为「QuantGPT」与「QuantBART」。
论文标题:CompressionofGenerativePre-trainedLanguageModelsviaQuantization
4、智能芯片清华大学:提出了一种基于金属-绝缘体-半导体结构的二维半导体电致发光器件结构。该研究是通过电场去加速材料中的已有载流子,加速载流子获得足够动能后,会和半导体价带的电子发生碰撞,这种碰撞带来的能量转移,会产生出发光所需要的激子。
论文标题:Injection-freemultiwavelengthelectroluminescencedevicesbasedonmonolayersemiconductorsdrivenbyanalternatingfield
西南交通大学、电子科技大学、中国海洋大学、北京基础医学研究所:中国科学家研发柔性脑机接口,在10Hz左右找到α波!实现刚性微电路和柔软脑组织的无缝联接。研究团队通过分子设计,制备出一款可导电的多功能水凝胶,借此实现了与脑组织接近的力学性能和生物学性能,刚性电子元件和柔软脑组织之间的机械和生物学不匹配的难题得以解决。
论文标题:Bioadhesiveandconductivehydrogelintegratedbrain-machineinterfacesforconformalandimmune-evasivecontactwithbraintissue
新加坡国立大学:研究报告了一种基于当前高速通信基础设施的生物识别保护技术。该系统包含一个协同摩擦电/光子接口,在接口中,柔性摩擦电器件提供生物识别扫描仪功能,氮化铝光芯片提供生物识别信息-光信息多路复用功能;在用户交互时,接口将生物特征信息加载到光域中,并通过摩擦电和纳米光子学之间的协同效应,以自我可持续的方式复用生物特征信息和数字信息;在云端,可以使用快速傅里叶变换滤波器分离高频数字信息和低频生物特征信息。
论文标题:Biometrics-protectedopticalcommunicationenabledbydeeplearning–enhancedtriboelectric/photonicsynergisticinterface
格芯、博通、CiscoSystems、Marvell、英伟达等:合作提出了硅光平台GFFotonix。该平台将差异化300mm光子功能和300GHz级别RF-CMOS结合在单个硅晶圆上,通过在单个硅芯片上组合光子系统、射频RF元件、CMOS逻辑电路,将以前分布在多个芯片上的复杂工艺整合到单个芯片上,实现了光子集成电路(PIC)上的更高集成度,让客户能够集成更多的产品功能,从而简化物料清单BOM。
英伟达:开发了全新GPU——H100,采用全新Hopper架构,集成了800亿个晶体管,比上一代A100多了260亿个,内核数量达到了前所未有的16896个,达到上一代A100卡的2.5倍,浮点计算和张量核心运算能力也随之翻了至少3倍,面向AI计算,针对Transformer搭载了优化引擎,让大模型训练速度直接×6,20张即可承载全球互联网流量。
苹果:发布搭载M1自研芯片的高端台式机,新产品名为MacStudio,起售价为1999美元,类似于专业版MacMini,可以与外部显示器相连。跟它匹配的,则是内置一颗A13新品的StudioDisplay显示器:苹果27寸显示器。
5、智能机器人华为:华为天才少年稚晖君推出了桌面迷你机器人ElectronBot,通过尝试用T-Spline曲面建模,并且机器人双臂可动,机器人的底座则使用铝CNC进行加工,使用了Cortex-M4内核MCU,STM32F4,用于驱动屏幕和控制舵机以及USB通信。此外,利用机器人机身搭载的摄像头和红外手持传感器,还开发了通过AI算法识别手势的程序。
微软:微软旗下MixedRealityAILab研究团队基于头显捕获的头部和手部追踪数据开发了“FLAG:FlowbasedAvatarGenerationfromSparseObservations”解决方案,通过VR头显获得的头部和手部追踪数据,可生成佩戴者的全身3D化身。它不仅能学习3D人体的条件分布,还能从观测数据中学习潜在空间的概率映射,并由此进行关节的不确定性估计,生成合理的姿势。
国网上海浦东供电公司:该公司在新片区开展全自主的双曲臂带电作业机器人作业。该机器人全自主作业成功率可达98%,配合了多传感器融合的定位系统,实现对导线毫米级识别定位。它采用双臂配合,能像人一样深度学习算法,运用人工智能技术,像人的大脑一样主动规划作业路径,高效完成工作任务。
北京术锐技术有限公司、上海交通大学医学院:国产单孔手术机器人共含68个高精度伺服电机,用于术前辅助摆位、术中操作和主从控制,创造性地设计了面向全状态安全监控的双环路独立控制硬件拓扑,全链路主从操作延时小于50毫秒,每秒钟可实现1000次的亚毫米级手术精准控制。
川崎重工:打造了世界首款四足机器羊Bex,可以降低机身,将下肢四腿膝部的轮毂接地,以四驱机车的方式前进,在有人模式下,羊骑士可以用Bex身上的手柄操纵行进方向与速度;在无人模式下,Bex可以被遥控、可以与其他川崎生产的无人自动送货机器人联网获取行动信息。
UC伯克利分校:将以前开发的机器人BADGR演变成ViKiNG,并将学习和规划集成起来,利用诸如示意路线图、卫星地图和GPS坐标等辅助信息作为规划启发式,利用基于图像的学习控制器和目标导向启发式(goaldirectedheuristic),在以前没见过的环境中导航到最远3公里以外的目标。
论文标题:ViKiNG:Vision-BasedKilometer-ScaleNavigationwithGeographicHints
中国人民大学、GeWu实验室:提出听音识物AI框架。AI先要在单一声源场景中学习物体的视觉-音频表征;然后再将这一框架迁移到多声源场景下,通过训练来辨别更多的声源。研究人员让这个框架先能从视觉方面定位出画面中存在的不同物体,然后再根据声音信息过滤掉不发声物体。这种方法还能迁移到物体检测任务中去。
麻省理工学院(MIT):开发了一种全新的“声感织物”(预制件的分层材料块,由压电层和响应声波振动的增强材料成分制成)。这种织物材料,不仅能够“听到”声音,还能“发出”声音。
论文标题:Singlefibreenablesacousticfabricsviananometre-scalevibrations
7、知识图谱魁北克人工智能研究院、加拿大蒙特利尔学习算法研究所:研究者在AAAI-2022会议论文中全面介绍知识图谱推理的不同方法,包括传统的基于符号逻辑规则的方法、基于神经的方法、神经符号方法、逻辑规则归纳方法和不同的应用。
论文标题:ReasoningonKnowledgeGraphs:SymbolicorNeural?
地址:
北京大学数据管理实验室:被TKDE2022接收的这篇论文对知识图谱质量控制问题展开了综述,不仅包括质量控制的基本概念如问题、维度和指标,也涵盖了质量控制从评估、问题发现到质量提升的全流程,对不同工作中提出的方法,按照多个维度进行分类,最后对现有工作进行讨论和总结,并提出了若干有潜力的未来发展方向。
论文标题:KnowledgeGraphQualityManagement:aComprehensiveSurvey
8、信息检索与推荐谷歌研究院:引入了可微搜索索引(DifferentiableSearchIndex,DSI)。这是一种学习文本到文本新范式,DSI模型将字符串查询直接映射到相关文档。此外,还研究了如何表示文档及其标识符的变化、训练过程的变化以及模型和语料库大小之间的相互作用。
论文标题:TransformerMemoryasaDifferentiableSearchIndex
上海交通大学:卢策吾团队提出了一种知识驱动的人类行为知识引擎HAKE(HumanActivityKnowledgeEngine)。它将像素映射到由原子活动基元跨越的中间空间;用一个推理引擎将检测到的基元编程为具有明确逻辑规则的语义,并在推理过程中更新规则。
论文标题:HAKE:AKnowledgeEngineFoundationforHumanActivityUnderstanding
9、可视化CMU、NUS、复旦、耶鲁大学:联合发布了面向文本数据的统一数据分析、处理、诊断和可视化平台DataLab。具有覆盖广、可理解性、统一性、可交互性、启发性几个特性。
论文标题:DataLab:APlatformforDataAnalysisandIntervention论文链接:
马里兰大学、莱斯大学、纽约大学:研究者对双下降(DoubleDescent)现象进行了可视化,从CIFAR-10训练集中选择了三幅随机图像,然后使用三次不同的随机初始化配置在7种不同架构上训练,绘制出各自的决策区域,并设计了一种更直观的度量方法来衡量各架构的可复现性得分,发现更宽的CNN模型似乎在其决策区域具有更高的可复现性。此外,优化器的选择也会带来影响。
论文标题:CanNeuralNetsLearntheSameModelTwice?InvestigatingReproducibilityandDoubleDescentfromtheDecisionBoundaryPerspective
陈·扎克伯格生物中心、莫纳什大学:开发了一个免费、开源并且可扩展的图像查看器napari,适用于任意复杂(“n维”)数据,与Python生态系统紧密结合,napari有类似于AdobePhotoshop的图层,允许用户叠加点、矢量、轨迹、表面、多边形、注释或其他图像。
论文标题:Pythonpower-up:newimagetoolvisualizescomplexdata
10、计算机系统美国AI芯片公司LuminousComputing:宣布已在A轮融资中筹集了1.05亿美元,用于建造世界上最强大的AI超级计算机,并将使用专有的硅光子学技术来消除各种规模的数据移动瓶颈。
美国国家标准与技术研究院:美国国家标准与技术研究院(NIST)的研究人员开发出新的可以在细胞内持续存在的长寿生物计算机。选择使用RNA来构建生物计算机。结果表明,RNA电路与其基于DNA的电路一样可靠和通用。更重要的是,活细胞能够连续创建这些RNA电路元件。
摩尔线程:张建中2020年9月离开英伟达,并于次月创办的摩尔线程发布国产第一代全功能GPU芯片苏堤,以及下一代多平台GPU物理仿真系统AlphaCore。该芯片耗时仅18个月、量产上市。采用了统一系统架构MUSA(MTUnifiedSystemArchitecture)。
11、AI应用清华大学、华深智药:清华大学和华深智药生物科技有限公司结合深度学习模型,完成了从抗体AI优化设计、抗体合成、功能评估和再优化的闭环程序,基于大量抗体-抗原复合物结构及结合亲和力数据,开发了一种基于注意力的几何神经网络架构,该模型可有效地提取残基间相互作用特征并预测由于抗体单个或多个氨基酸变化所引起的结合亲和力变化。
论文标题:DeeplearningguidedoptimizationofhumanantibodyagainstSARS-CoV-2variantswithbroadneutralization
德国ALSVoicegGmbH:德国ALSVoicegGmbH展示了一种使用计算机从脑信号解码字母的方法,可以使完全闭锁患者借助脑机接口(BCI)进行语言交流。目前已经可以和一名34岁、完全闭锁状态的男性ALS患者(已无法控制随意肌),以每分钟一个词的速度形成单词和词组进行交流。
论文标题:Spellinginterfaceusingintracorticalsignalsinacompletelylocked-inpatientenabledviaauditoryneurofeedbacktraining
中国科学院:中国科学院微生物研究所结合LSTM、Attention和BERT等多种自然语言处理神经网络模型,建立了一个用于从人类肠道微生物组数据中识别候选腺苷-磷酸(AMP)的统一管道,利用现已公开的大量宏基因组数据,进行多肽的挖掘及逻辑推导,研究合成多肽的机理、安全性与动物实验等,并得出对真核细胞没有明显毒性的肽能够在动物体内降低感染菌的载量,并有效治疗肺炎克雷伯菌所导致的感染。
论文标题:Identificationofantimicrobialpeptidesfromthehumangutmicrobiomeusingdeeplearning
GoogleResearch:GoogleResearch提出了一个机器学习模型ProtENN,能够可靠地预测蛋白质的功能,并且为Pfam新增了大约680万条蛋白质功能注释,大约相当于过去十年进展的总和。
论文标题:UsingDeepLearningtoAnnotatetheProteinUniverse
清华大学、伊利诺伊大学厄巴纳-香槟分校、麻省理工学院:清华大学、伊利诺伊大学厄巴纳-香槟分校和麻省理工学院利用DeepMind开发的第二代深度学习神经网络AlphaFold2增强新冠抗体,可以使抗体宽度以及sarscov-2变体(包括Delta)的效力提高10到600倍」,甚至发现了该方法可以对抗奥密克戎(Omicron)变体迹象的希冀。
论文标题:DeeplearningguidedoptimizationofhumanantibodyagainstSARS-CoV-2variantswithbroadneutralization
厦门大学、新加坡国立大学:张鹏和陈宇综等学者的团队正在研究如何借助计算机算法从蛋白质中创作古典音乐。一条蛋白质链可以表示为一个由字母组成的字符串,像一个以字母表示的音符串。因此,一种合适的“蛋白质到音乐”的算法,就可以将一串氨基酸的结构和物理化学特征映射到一段音符的音乐特征上。
论文标题:Proteinmusicofenhancedmusicalitybymusicstyleguidedexplorationofdiverseaminoacidproperties
潞晨科技、上海交大:潞晨科技和上海交大提出了一种蛋白质结构预测模型的高效实现FastFold,FastFold包括一系列基于对AlphaFold性能全面分析的GPU优化,同时,通过动态轴并行和对偶异步算子,FastFold提高了模型并行扩展的效率,超越了现有的模型并行方法。
论文标题:FastFold:ReducingAlphaFoldTrainingTimefrom11Daysto67Hours
谷歌AI:谷歌AI发布了用于蛋白质解析的机器学习模型ProtENN,可以帮助在Pfam的蛋白质功能注释集中添加大约680万个条目,大约相当于过去十年的新增条目总和,将Pfam的覆盖范围扩大了9.5%以上。
论文标题:UsingDeepLearningtoAnnotatetheProteinUniverse
麻省理工学院、哈佛大学:麻省理工学院、哈佛大学博德研究所开发了一种新框架来研究调控DNA的适应度地形,该研究利用在数亿次实验测量结果上进行训练的神经网络模型,预测酵母菌DNA中非编码序列的变化及其对基因表达的影响。
论文标题:Theevolution,evolvabilityandengineeringofgeneregulatoryDNA
美国德州农工大学:德州农工大学基于机器学习的培养设计和合成生物学的平台,突破了藻类生产中“相互遮荫”和“高收获成本”的限制,实现43.3克/平方米/天的生物质产量,使最低生物质销售价格降至每吨约281美元。
论文标题:Machinelearning-informedandsyntheticbiology-enabledsemi-continuousalgalcultivationtounleashrenewablefuelproductivity
哥本哈根大学、米兰大学等:丹麦、瑞士、法国、德国、挪威和捷克共和国的16名研究人员,首次开发了一款人工智能,可以把猪在各种场景中发出的声音“翻译”出来,读出猪的真实情绪,通过记录411头家猪的7000多次猪叫,使用训练算法来识别这些声音,可以以92%的正确率翻译出猪叫声中的情绪。
论文标题:Classificationofpigcallsproducedfrombirthtoslaughteraccordingtotheiremotionalvalenceandcontextofproduction
DeepMind、哈佛大学、谷歌:DeepMind、哈佛大学和谷歌等联合开发了一种基于Transformer架构的方法,单独修复受损文本时,准确率能达到62%,破译古希腊石碑的准确率达到72%,此外,这一方法在地理归属的任务上也有71%的准确率,还能将古文字的书写日期精确到30年以内。
西安电子大学、悉尼科技大学等:中国和澳大利亚学者开发了一款名为的电子鼻,里面有一小瓶威士忌样品,威士忌的气味被注入到一个气体传感器室中,气体传感器检测各种气味并将数据发送给计算机进行分析。然后,通过机器学习算法提取和分析最重要的气味特征,以识别威士忌的品牌、地区和风格。
科大讯飞:科大讯飞为两会打造了“讯飞听见智慧简报系统”。通过智能语音转写、自然语言处理等多项核心技术,该系统实现了在全程离线环境下将会议发言实时转写成文字,一方面辅助记录人员进行简报材料整理,既保证简报记录原汁原味,又保证内容准确详实,另一方面所有算法均在设备本机离线运行,确保会议信息安全。
卡内基梅隆大学:卡内基梅隆大学开发了一个名为MolCLR(MolecularContrastiveLearningofRepresentationswithGNN)的自我监督学习框架,通过利用大约1000万个未标记的分子数据,显著提高了ML模型的性能,继而进行化学研究。
论文标题:Molecularcontrastivelearningofrepresentationsviagraphneuralnetworks
布朗大学、MIT、南洋理工大学:布朗大学、MIT和南洋理工大学提出了一种基于PINN的方法,用于解决连续体固体力学中的几何识别问题,该方法将固体力学中重要的已知偏微分方程(PDE)与NN相结合,构成了一个统一的计算框架,包括正向求解器和逆向算法,通过使用神经网络的工作流程,该方法可以通过深度学习过程自动更新几何估计。
论文标题:Analysesofinternalstructuresanddefectsinmaterialsusingphysics-informedneuralnetworks
斯坦福大学、天津大学:斯坦福大学、天津大学设计了一种极富弹性的可穿戴显示器——可拉伸全聚合物发光二极管(APLED),APLED具有很好的明亮度和耐用性,这一设计或标志着高性能可拉伸显示器的重要进展,为电子皮肤和人-电子应用奠定基础。
论文标题:High-brightnessall-polymerstretchableLEDwithcharge-trappingdilution
清华AIR、计算机系与腾讯AILab:清华AIR、计算机系与腾讯AILab共同提出了图力学网络(GraphMechanicsNetwork,GMN)。借助广义坐标,GMN能有效刻画几何约束;借助等变神经网络,GMN能满足物理对称性。在多刚体仿真系统ConstrainedN-body、人体骨架预测CMUMotionCapture、分子动力学模拟MD-17等任务上都验证了GMN的有效性。
论文标题:EquivariantGraphMechanicsNetworkswithConstraints
RIKEN、东京大学:RIKEN高级智能项目研究中心和东京大学使用从头分子生成器(DNMG)与量子化学计算(QC)相结合来开发荧光分子,使用大规模并行计算(1024核,5天),DNMG产生了3643个候选分子。光致发光光谱测量表明,DNMG可以以75%的准确度(n=6/8)成功设计荧光分子,并产生一种未报告的分子,该分子发出肉眼可检测到的荧光。
论文标题:Denovocreationofanakedeye–detectablefluorescentmoleculebasedonquantumchemicalcomputationandmachinelearning
萨塞克斯大学、伦敦大学学院:萨塞克斯大学、伦敦大学学院的研究着提出了一种采用机器学习方法,通过观察自动发现实际物理系统的控制方程和隐藏属性。该研究分为两个阶段:第一阶段的学习模拟器基于图网络(GN),图网络是一种深度神经网络,可以通过训练来逼近图上的复杂函数;第二阶段,该研究分离边函数(edgefunction),并应用符号回归拟合边函数的解析公式,其最好的拟合是对牛顿万有引力定律的拟
合。
论文标题:Rediscoveringorbitalmechanicswithmachinelearning
巴西ABC联邦大学:巴西ABC联邦大学提出了一种数据驱动策略来探索二维材料中的磁性。使用创建的二维磁性材料数据库训练ML算法,从而获得能够将材料分类为非磁性、FM或AFM的描述符。该策略分为两个主要步骤,即(i)开发一个随机森林模型,根据晶体结构和原子组成趋势将磁性与非磁性化合物分开,以及(ii)基于确定的独立性通过筛选和稀疏算子(SISSO)方法寻找一个数学模型(即原子特征的函数),该模型为AFM和FM二维材料提供具有定义区域的材料图。
论文标题:MachineLearningStudyoftheMagneticOrderingin2DMaterials
苏黎世联邦理工学院:苏黎世联邦理工学院提出可使用自学习的人工神经网络,解决动力系统的控制问题。利用数值和分析方法的结合,AIPontryagin可通过自动学习,找出工程上可行的控制系统的方式。该方法可应用于智能电网的调控、供应链优化以及金融系统的稳定等众多场景。
论文标题:AIPontryaginorhowartificialneuralnetworkslearntocontroldynamicalsystems
AI+自动驾驶:清华大学、麻省理工学院提出了一种基于自监督学习的方法,让自动驾驶模型从已有的轨迹预测数据集中学会正确判断冲突中的礼让关系。该研究将预测的关系在充满复杂交互的WaymoInteractiveMotionPrediction数据集上进行了测试,并提出了M2I框架来使用预测出的关系进行场景级别的交互轨迹预测。
论文标题:M2I:FromFactoredMarginalTrajectoryPredictiontoInteractivePrediction
麻省理工学院的Derq分支机构,开发了一个人工智能应用程序,可以融合来自多个传感器的数据,包括安装在车辆和道路两侧的摄像头,以监测并最终协助管理道路,提高安全性。
AI+气候能源:康奈尔大学开发了一个基于机器学习的多时间尺度的电力系统脱碳过渡优化模型,旨在帮助政府规划电力部门向碳中和过渡的路径,以及考量气候或能源目标的可行性。
论文标题:TowardCarbon-NeutralElectricPowerSystemsintheNewYorkState:aNovelMulti-ScaleBottom-UpOptimizationFrameworkCoupledwithMachineLearningforCapacityPlanningatHourlyResolution
英伟达、劳伦斯伯克利国家实验室、密歇根大学安娜堡分校、莱斯大学等机构开发了一种基于傅里叶的神经网络预测模型FourCastNet,它能以0.25°的分辨率生成关键天气变量的全球数据驱动预测,相当于赤道附近大约30×30km的空间分辨率和720×1440像素的全球网格大小。这使得首次能够与欧洲中期天气预报中心(ECMWF)的高分辨率综合预测系统(IFS)模型进行直接比较。
论文标题:FourCastNet:AGlobalData-drivenHighresolutionWeatherModelusingAdaptiveFourierNeuralOperators
智东西认为,三月的AI领域重大新闻数量有所下降,但质量上一点也没缩水。最重磅的,当属NVIDIAOmniverse全新功能,用AI技术提升游戏画面,让人物表情变得栩栩如生。另外,中国相关的AI领域的表现也十分亮眼,浙大博士入选苹果奖学金,十一大AI细分领域中都有中国相关高校、公司的身影。



