
第一步,先对一个验证码进行处理,
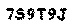
,①目标是将图片尽量简化成黑白,②然后切割出单字符,对此使用的是PIL的Image库。
①导入图片,转换成8位像素的图片
将颜色作为键,出现次数作为值,形成字典foriinrange(256):values[i]=his[i]构造一个纯白的等大小的图片im2im2=("P",,255)[1]是垂直像素数foryinrange([0]):获取每一个像素点的颜色纸ifpix==220orpix==227:符合则变成黑色之后用(),可以看到这个
很符合我们的想法
②然后我们需要切割出单个字符,实验楼里面说:“由于例子比较简单,我们对其进行纵向切割:”,恕我刚刚接触时间不长,还不太能了解这句话后面的深度
具体做法就是纵向从左到右“一刀刀往下切”
一个变量判断是否切到了黑色的像素点,切到则转换“刀”为切到字符的状态并且记录当前的水平位置,
如果没有切到黑色像素点,但是“刀”依旧是切到字符的状态,则重置“刀”为未切到字符的状态并且当前的记录水平位置,
第一次记录的位置到第二次记录的位置一定有一个字符。
inletter=False未切到字符的状态记录start=0记录结束的x值letters=[]纵向切割记录数据forxinrange([0]):同一水平值下遍历垂直的(用刀切)pix=((x,y))碰到黑色就位切到了inletter=True如果上面if没有成立,则下面的if不会发生,所以letters一定会记录到2个不同的值重置为未切到字符inletter=False
打印letters,符合预期
[(6,14),(15,25),(27,35),(37,46),(48,56),(57,67)]
然后将记录到的数据,对图片进行切割
参数一个四元组,四个元素依次是左上角的x和y值与右下角的x和y值im3=((letter[0],0,letter[1],[1]))
然后可以遍历保存im3为.gif格式,可以得到6个图片
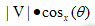
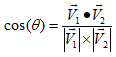
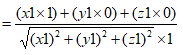
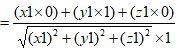
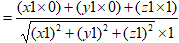

都是单独的字符了,至此第一步完成
接下来就是核心的第二步,怎么把每一个字符输出对应的数字?
首先是实验楼给出的论文网站,
“也说了这个这个方法的优缺点:
不需要大量的训练迭代
不会训练过度
你可以随时加入/移除错误的数据查看效果
很容易理解和编写成代码
提供分级结果,你可以查看最接近的多个匹配
对于无法识别的东西只要加入到搜索引擎中,马上就能识别了。
当然它也有缺点,例如分类的速度比神经网络慢很多,它不能找到自己的方法解决问题等等。”
然后实验楼只是简单的介绍了一下原理,并未详细说明,为此我通读了整篇论文,来说说我的一点理解。

在x轴上的投影为
在向量大小为定值时,夹角越小,余弦越大,则投影越大,所以我们不用计算出具体的投影的值,问题转化成了求夹角的余弦即可。
两向量的夹角公式
带入相应的数值即可得到
即可知道和x轴夹角,同理与y轴夹角
与z轴夹角
之后只需要找出最大的余弦值,对应的字符就是最相关的。
这是基本矢量空间搜索引擎理论的含义,然后将这个方法用于图片,会变得更加的复杂,但是核心思想并未改变。
然后我们照着改一下。
参数是字符的图片d1={}用来增加像素点位置():把颜色值作为值加入字典count+=1returnd1比较矢量相似度的类classVectorCompare:word像素点位置,count对应的颜色(0或255)total+=count**2(total)计算矢量的夹角defrelation(self,concordance1,concordance2):求余弦公式的分子forword,():每一维度(像素点),两向量的颜色值(0或255)相乘,求出余弦公式分子topvalue+=count*concordance2[word]all_magnitude=(concordance1)*(concordance2)求出余弦returnrelevance训练集名字iconset=['0','1','2','3','4','5','6','7','8','9','a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y','z'][{正确名字1:[字典化图片]},{正确名字2:[字典化图片]},{正确名字3:[字典化图片]}。。。]遍历iconset所有要训练的名字("./iconset/%s"%(letter)):列表用来记录字典化图片ifimg!=""andimg!=".DS_Store":生成字典化图片({letter:temp})判断单个字符的相似度str=""记录和所有训练集的数据,用来排序forimageinimageset:x是正确名字,y是对应的[字典化图片]iflen(y)!=0:y[0]就是字典化图片(reverse=True)相似度最高的字符加到字符串里print(str)比较矢量相似度的类classVectorCompare:word像素点位置,count对应的颜色(0或255)total+=count**2(total)计算矢量的夹角defrelation(self,concordance1,concordance2):求余弦公式的分子forword,():同一维度(像素点),两向量的颜色值(0或255)相乘,求出余弦公式分子topvalue+=count*concordance2[word]all_magnitude=(concordance1)*(concordance2)求出余弦returnrelevance图片转换成矢量,字典化图片defbuildvector(im):字典记录像素点位置和对应的颜色count=0i就是从0开始对应的颜色值d1[count]=i返回{像素点位置:颜色}的字典训练集名字iconset=['0','1','2','3','4','5','6','7','8','9','a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y','z'][{正确名字1:[字典化图片]},{正确名字2:[字典化图片]},{正确名字3:[字典化图片]}。。。]遍历iconset所有要训练的名字("./iconset/%s"%(letter)):列表用来记录字典化图片ifimg!=""andimg!=".DS_Store":生成字典化图片({letter:temp})加载图片并且转换成8位像素im=("./")("P")遍历加载的图片,对每个像素点判断是否符合要求forxinrange([1]):[0]是水平像素数pix=((y,x))判断是否符合220或者227((y,x),0)判断是否切割到了字符foundletter=False记录开始的x值=0记录切割到的字符遍历水平的像素点foryinrange([1]):获取像素点颜色ifpix!=255:切到但是刀的状态是没有切到,则转换刀的状态为切到iffoundletter==Falseandinletter==True:foundletter=Truestart=x没有切到但是刀的状态是切到了,则转换刀的状态为未切到iffoundletter==Trueandinletter==False:foundletter=False=((start,))判断单个字符的相似度str=""记录和所有训练集的数据,用来排序forimageinimageset:x是正确名字,y是对应的[字典化图片]iflen(y)!=0:y[0]就是字典化图片(reverse=True)相似度最高的字符加到字符串里之后便要对所有的examples文件夹下的验证码都进行训练,看看准确度如何
从加载图片到最后的判断字符都放入一个for循环语句当中
("./examples"):以及验证码图片的加载也要修改为
iflistname!=""andlistname!=".DS_Store":im=("./examples/%s"%(listname))("P")下面的所有代码都要这个if条件下才能实施,全部再缩进一行
当我再次打印输出的时候显示的验证码结果是
0q1dp00q3tje24alb0p47j17b4wwfa5dwvo5t0qh75rc1qp7s9t9jbibfkfbf5te9f2luc9tmxf9to1tkpakfvavaro2hzb17lzhb3rk8hb3ufl9pbmk5jx2mybtcw0qycfyrgeb0qy3etg5zfnt5xphd0qliivusjvjfte2zttiqk0qg4lk6e2irw0qlkw7k5zl9felglz73a7t1sgen67dmbnlrzo7tmisvf15jndfmiunqqfwix9r2lvkdr6r12e718ftt6khwibrjcpuc1rdkv63gde7f54egxfnrsn
有长有短,但是验证码的长度应当是6个字符,对错我也并不知晓,所以我开始着手准备
我在循环前加了一系列变量用来记录我所疑惑的
success=0记录失败的个数success_name_list=[]记录失败的名字wrong_length_name=[]记录失败的对应的字母错误并累加记录次数correct_name_list=[]记录正确的文件名,用来判断是否正确
然后就是对结果str进行判断,并记录相关数据
ifstr==correct_name:正确次数加1success_name_(str)错误次数加1fail_name_(str)同时记录对应的正确名字用来进一步分析
最后就是将相关数据汇总分析,我尽我能力全分析了,过程具体注释也就不详细写了,
count=0统计出错误的原因forlettersinfail_name_list:长度统一,但是识别错误else:index=0forletterinletters:ifletter!=correct_name_list[count][index]:wrong_letter_count_dict[letter]=wrong_letter_count_(letter,0)+1index+=1else:index+=1count+=1success_rate=success/(success+fail)打印总数,成功和失败的数量,以及成功率print("totalcount={}\n""success={},failed={}\n""success_rate={}\n".format(success+fail,success,fail,success_rate))去除长度识别错误的数量success_rate=success/(success+fail-wrong_length_count)打印错误长度的验证码的数量print("\nWrongLengthcount:{}".format(wrong_length_count))print("totalcountwithoutwronglength={}\n""success={},failed=withoutwronglength={}\n""success_ratewithoutwronglength={:.4f}\n".format(success+fail-wrong_length_count,success,fail-wrong_length_count,success_rate))比较矢量相似度的类classVectorCompare:word像素点位置,count对应的颜色(0或255)total+=count**2(total)计算矢量的夹角defrelation(self,concordance1,concordance2):求余弦公式的分子forword,():同一维度(像素点),两向量的颜色值(0或255)相乘,求出余弦公式分子topvalue+=count*concordance2[word]all_magnitude=(concordance1)*(concordance2)求出余弦returnrelevance图片转换成矢量,字典化图片defbuildvector(im):字典记录像素点位置和对应的颜色count=0i就是从0开始对应的颜色值d1[count]=i返回{像素点位置:颜色}的字典训练集名字iconset=['0','1','2','3','4','5','6','7','8','9','a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y','z'][{正确名字1:[字典化图片]},{正确名字2:[字典化图片]},{正确名字3:[字典化图片]}。。。]遍历iconset所有要训练的名字("./iconset/%s"%(letter)):列表用来记录字典化图片ifimg!=""andimg!=".DS_Store":生成字典化图片({letter:temp})记录正确匹配个数fail=0记录正确匹配的名字fail_name_list=[]记录失败的错误长度的名字wrong_letter_count_dict={}记录错误所对应的正确名字,列表下标对应对比容易("./examples"):correct_name=listname[:6]加载图片并且转换成8位像素iflistname!=""andlistname!=".DS_Store":im=("./examples/%s"%(listname))("P")遍历加载的图片,对每个像素点判断是否符合要求forxinrange([1]):[0]是水平像素数pix=((y,x))判断是否符合220或者227((y,x),0)判断是否切割到了字符foundletter=False记录开始的x值=0记录切割到的字符遍历水平的像素点foryinrange([1]):获取像素点颜色ifpix!=255:切到但是刀的状态是没有切到,则转换刀的状态为切到iffoundletter==Falseandinletter==True:foundletter=Truestart=x没有切到但是刀的状态是切到了,则转换刀的状态为未切到iffoundletter==Trueandinletter==False:foundletter=False=((start,))判断单个字符的相似度str=""记录和所有训练集的数据,用来排序forimageinimageset:x是正确名字,y是对应的[字典化图片]iflen(y)!=0:y[0]就是字典化图片(reverse=True)相似度最高的字符加到字符串里ifstr==correct_name:正确次数加1success_name_(str)错误次数加1fail_name_(str)同时记录对应的正确名字用来进一步分析count=0统计出错误的原因forlettersinfail_name_list:长度统一,但是识别错误else:index=0forletterinletters:ifletter!=correct_name_list[count][index]:wrong_letter_count_dict[letter]=wrong_letter_count_(letter,0)+1index+=1else:index+=1count+=1success_rate=success/(success+fail)打印总数,成功和失败的数量,以及成功率print("totalcount={}\n""success={},failed={}\n""success_rate={}\n".format(success+fail,success,fail,success_rate))去除长度识别错误的数量success_rate=success/(success+fail-wrong_length_count)打印错误长度的验证码的数量print("\nWrongLengthcount:{}".format(wrong_length_count))print("totalcountwithoutwronglength={}\n""success={},failed=withoutwronglength={}\n""success_ratewithoutwronglength={:.4f}\n".format(success+fail-wrong_length_count,success,fail-wrong_length_count,success_rate))#将字母识别错误1的输出,用来表示标准样本的错误wrong_letter_count_list=sorted(wrong_letter_count_(),key=lambdax:x[1],reverse=True)forletterinwrong_letter_count_list:ifletter[1]1:print("Needmore{}totrain".format(letter[0]))



