本文并不是要从这些解决方案中指定一个最优集合,而是给出一篇概述,介绍精选的5个流行库,希望能帮助解决你的问题。
1.HuggingFaceDatasetsHuggingFace的Datasets库本质上是一个对公开可用的NLP数据集的打包集合,带有一组通用的API和数据格式,以及一些辅助功能。以下是关于它的介绍:
你可以通过以下方式轻松安装Datasets库:
pipinstalldatasets
复制代码
根据介绍,Datasets提供了两大特性:用于许多公共数据集的单行数据加载器,以及高效的数据预处理。但它的介绍没有提到这个库的另一大特性:与NLP任务相关的许多内置评估指标。这个库还有其他一些特性,例如数据集的后端内存管理以及与流行的Python工具(如NumPy、Pandas)和主流机器学习平台(TensorFlow和PyTorch)的互操作性。
我们先来看看如何加载一个数据集:
fromdatasetsimportload_dataset,list_datasetsprint(f"TheHuggingFacedatasetslibrarycontains{len(list_datasets())}datasets")squad_dataset=load_dataset('squad')print(squad_dataset['train'][0])print(squad_dataset)复制代码
TheHuggingFacedatasetslibrarycontains635datasetsReusingdatasetsquad(/home/matt/.cache/huggingface/datasets/squad/plain_text/1.0.0/4c81550d83a2ac7c7ce23783bd8ff36642800e6633c1f18417fb58c3ff50cdd7){'answers':{'answer_start':[515],'text':['SaintBernadetteSoubirous']},'context':'Architecturally,\',isacopperstatueofChristwitharmsupraisedwiththeleg"VeniteAdMeOmnes".,,Francewher(andinadirectlinethatconnectsthrough3statuesandtheGoldDome),isasimple,modernstonestatueofMary.','id':'5733be284776f41900661182','question':'TowhomdidtheVirginMaryallegedlyappearin1858inLourdesFrance?','title':'University_of_Notre_Dame'}DatasetDict({train:Dataset({features:['id','title','context','question','answers'],num_rows:87599})validation:Dataset({features:['id','title','context','question','answers'],num_rows:10570})})复制代码
加载指标也很简单:
复制代码
TheHuggingFacedatasetslibrarycontains19metricsAvailablemetricsare:['accuracy','bertscore','bleu','bleurt','comet','coval','f1','gleu','glue','indic_glue','meteor','precision','recall','rouge','sacrebleu','seqeval','squad','squad_v2','xnli']
复制代码
你想用它们做什么都随意,但有了这个库,你就可以轻松加载可公开访问的数据集,和久经考验的真实评估指标了。
2.TextHeroTextHero在其GitHub存储库中的介绍很简单:
这几句话很好地解释了这个库可以解决的问题,下面我们再深入研究一下为什么我们就要用它。从repo中我们可以看到更具体的说明:
现在你知道了为什么要使用TextHero,它的安装方法如下:
pipinstalltexthero
复制代码
入门指南介绍了你可以用它做的工作,几行代码就可以搞定。使用TextHeroGithub存储库中的以下示例,我们会加载一个数据集,清理它,并创建一个TF-IDF表示,执行主成分分析(PCA)并绘制PCA的结果。
deftext_texthero():importtextheroasheroimportpandasaspddf=_csv("")df['pca']=(df['text'].pipe().pipe().pipe())(df,'pca',color='topic',title="PCABBCSportnews")复制代码
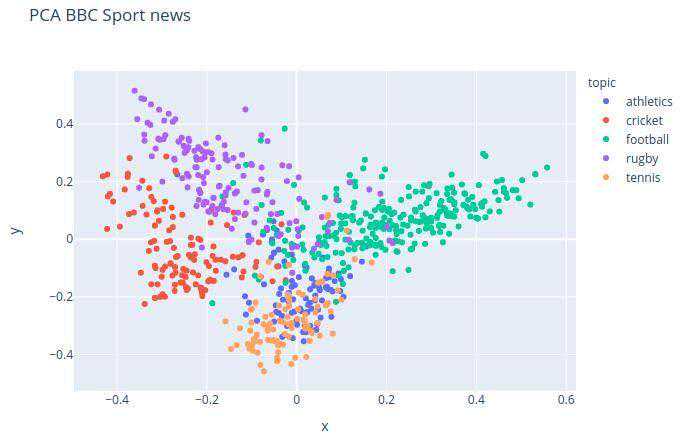
用TextHero可以完成的工作还有很多,请继续查阅文档,了解数据清理和预处理、可视化、表示、基本NLP任务等相关信息。
3.spaCyspaCy是专门设计的,其宗旨是成为一个用于实现生产就绪系统的有用库。以下是关于它的介绍:
所以当你准备开始做一些真正的工作时,你需要先安装spaCy和至少一个语言模型。在下面这个例子中我们将使用它的英语语言模型。库和语言模型只需几行代码即可安装:
pipinstallspacypython-mspacydownloaden
复制代码
要开始使用spaCy,我们将使用示例文本的这句话:
sample=u"Ican'timaginesping$3000"
复制代码
现在我们导入spaCy和一个英文停用词列表。我们还将英语语言模型作为Language对象加载(根据spaCy约定,我们将其称为“nlp”),然后在示例文本上调用nlp对象,它会返回一个经过处理的Doc对象(我们将其称为“doc”)。
_wordsimportSTOP_WORDSnlp=('en')doc=nlp(sample)复制代码
这样就行了?根据spaCy文档:
现在我们来看看处理过的样本:
Identifystopwordsprint("Stopwords:\n===========")forwordindoc:_stop==True:print(word)Printoutnamedentitiesprint("Namedentities:\n==============="):print(,_char,_char,_)复制代码
Tokens:=======Ican'timaginesping$3000:===========caforainPOStagging:============I-PRON-PRONPRPnsubjXTrueFalsecacanVERBMDauxxxTrueTruen'tnotADVRBnegx'xFalseFalseimagineimagineVERBVBROOTxxxxTrueFalsespingspVERBVBGxcompxxxxTrueFalse$$SYM$nmod$FalseFalse30003000NUMCDdobjddddFalseFalseforforADPINprepxxxTrueTrueaaDETDTdetxTrueTruesinglesingleADJJJamodxxxxTrueFalsebedroombedroomNOUNNNcompoundxxxxTrueFalseap:===============30002630
复制代码
spaCy功能强大、坚持己见(opinionated),可用于从预处理到表示再到建模的各种NLP任务。查看spaCy文档,看看你可以用它做哪些事情。
4.HuggingFaceTransformersHuggingFace的Transformers库已成为NLP实践不可或缺的一部分,这一点再怎么强调也不为过。根据GitHub存储库的介绍:
你可以使用WriteWithTransformer在线测试Transformer库,这是该库的官方功能演示。
这个很复杂的库安装起来却很简单:
pipinstalltransformers
复制代码
Transformers库包罗万象,你可以花很多时间学习它的所有细节。然而,它自带的管道API让你可以立即使用模型,几乎不需要配置。以下是使用Transformers管道进行分类的一个示例(请注意,应先安装TensorFlow或PyTorch才能继续):
fromtransformersimportpipelineClassifytextprint(classifier('IamafanofKDnuggets,itsusefulcontent,anditshelpfuleditors!'))复制代码
[{'label':'POSITIVE','score':0.9954679012298584}]复制代码
多简单,很有趣吧。这个管道使用了一个预训练的模型以及用于该模型的预处理,即使没有微调,结果也非常不错。
下面是第二个管道示例,这次是问题回答:
fromtransformersimportpipelineAskaquestionanswer=question_answerer({'question':'WhereisKDnuggetsheadquartered?','context':'KDnuggetswasfoundedinFebruaryof1997byGregoryPiatetskyinBrookline,Massachusetts.'})#Printtheanswerprint(answer)复制代码
{'score':0.99065,'start':66,'':90,'answer':'Brookline,Massachusetts'}复制代码
当然上面是一对简单的示例,但这些管道非常强大,绝不止是解决一些与KDnuggets相关的琐碎任务那么简单!你可以在此处阅读有关管道的更多信息。
Transformers让最先进的模型也能轻松供所有人使用。请访问它的GitHub存储库,探索更多精彩。
5.ScattertextScattertext用于创建吸引人的可视化图像,来描述语言在不同文档类型之间的差异。根据其GitHub仓库的介绍:
还没搞懂的话,我们先来安装它:
pipinstallscattertext
复制代码
以下示例来自它的GitHub存储库,可视化了2012年美国大选中使用的术语。
请注意,运行示例代码会生成一个HTML文件,然后可以在浏览器中查看该文件并与之交互。
importscattertextasstdf=_data().assign(parse=lambdadf:(_nlp_with_sentences))corpus=(df,category_col='party',parsed_col='parse').build().get_unigram_corpus().compact((2000))html=_scattertext_explorer(corpus,category='democrat',category_name='Democratic',not_category_name='Republican',minimum_term_frequency=0,pmi_threshold_coefficient=0,width_in_pixels=1000,metadata=_df()['speaker'],transform=_rank)open('./demo_','w').write(html)复制代码
查看时保存的HTML文件的结果(下面显示的是静态图像,因此不是交互式的):
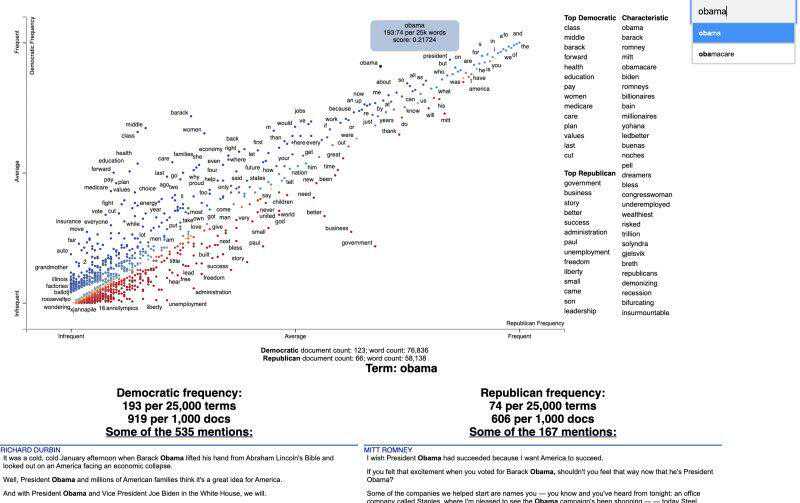
Scattertext的用途很窄,但效果很好。它的可视化输出绝对很漂亮,而且富含见解。
")


