年初的华为P30系列发布会上华为发布了方舟编译器,一经发布众说纷纭,甚至有一些全民讨论编译器的架势,最近的开源也是如此。这是不是一件好事儿不好说,还是不要急着下结论的好,编译器也好,操作系统也好,数据库也好,这些大型基础软件是否成功应该以十年计,方舟能否成功不要急着下结论,最近参加了华为方舟编译器首场开源技术沙龙,透漏了很多有价值的信息,分享给大家。
为什么要做编译器?为什么开源?GCC和LLVM已经很成熟的编译器架构了为什么要做方舟编译器?出发点和目的是什么?方舟编译器有哪些特性吸引用户去用?一款产品想成功和持续下去必须要有生存的土壤,这一点很关键,有人持续的使用才会有不断的更新完善。
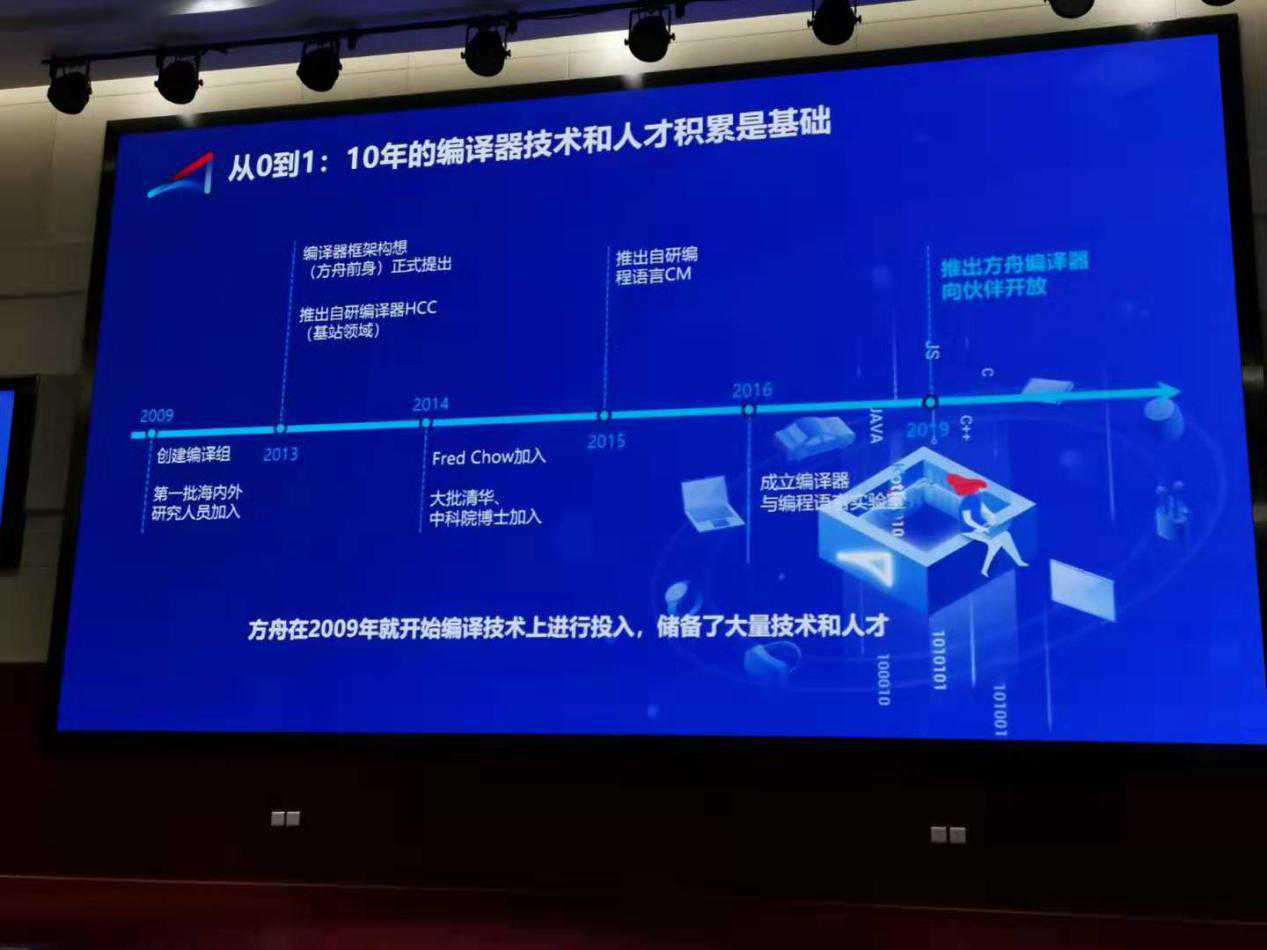
方舟编译器架构师说,华为做编译器有近10年历史了,最初是为了解决无线基站DSP的手写汇编问题在2009年成立了编译器团队并基于GCC做了编译后端。2014年Open64的鼻祖,大名鼎鼎的FredChow加入了华为并开始主导方舟编译器,2015年的时候依然是无线基站的DSP问题,汇编语言是低级的语言与硬件关联性非常紧密,写起来麻烦不说换芯片就要重新适配也是非常麻烦的,于是华为将C语言和Matlab的数据类型和操作结合做了一个CM语言,来解决这个问题,配合编译取得了很好的效果。2016年之后华为的手机也是越卖越好,手机研发上也遇到一些问题,于是开始将在无线端应用的编译器引入进来,一直到现在才有了方舟编译器。
方舟编译器首先解决的是华为内部无线基站研发的痛点,有着这样的基础方舟编译器就会一直被使用下去,现在引入手机终端部门很大一部分原因是JAVA的原因。虚拟机是JAVA的精髓所在,虚拟机带来的好处是以性能为代价的,那么那些必须考虑效率的库和应用怎么办呢?用JNI(Javanativeinterface)技术调用C/C++库,又是一笔不必要的开销,JAVA的GC停顿也是一大问题。方舟编译器与其说是解决Android的问题不如说是解决JAVA的问题,那这里有个疑问华为会重新发布一门语言吗?好像有点远了。
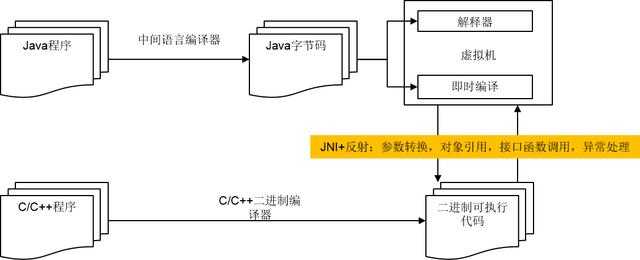
Android在5.0之后将Dalvik虚拟机替换为ART虚拟机,这也是AndroidRuntime,在几经更改之后现在Android采用的是"解释执行+JIT+AOT"的混合编译策略。方舟编译器要去掉ART虚拟机是可行的,但是JAVA的反射机制、内存管理还是要有Runtime的,所以方舟编译器有一个面向内部的轻量型Runtime。目前开发者可以先在华为手机上运行,同时华为也希望可以在社区通过开源的方式做一个简单的Runtime。后续会按照计划尽快开放所有源代码。
做编译器为什么要开源,之前做无线基站的编译的时候也没开源呀,苹果也有很多产品没开源呀,自己用不是挺好的吗?一方面,方舟开源能够获取更多开发者对方舟技术的信心和支持。另一方面来说,方舟开源对对整个开源社区甚至是国内的编译器的发展都会有好处。
多层IR的构想MIR本次方舟编译器开源最主要的部分是IR(IntermediateRepresentation),这是一个中间表示层,IR前面的称之为前端,后面的称之为后端,JAVA的字节码本质上也是一种IR表示。
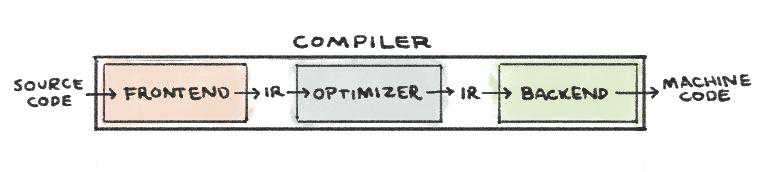
想要支持多语言,多硬件架构,IR是必须的,LLVM也是如此。
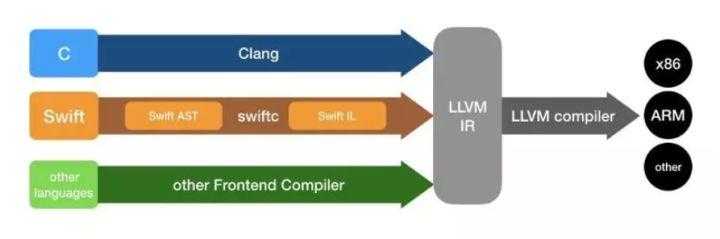
方舟编译器团中有一个在编译器行业的大名鼎鼎的前辈FredChow,他也是Open64的鼻祖,方舟编译器的MapleIR设计也是起源于FredChow的大一统思想。
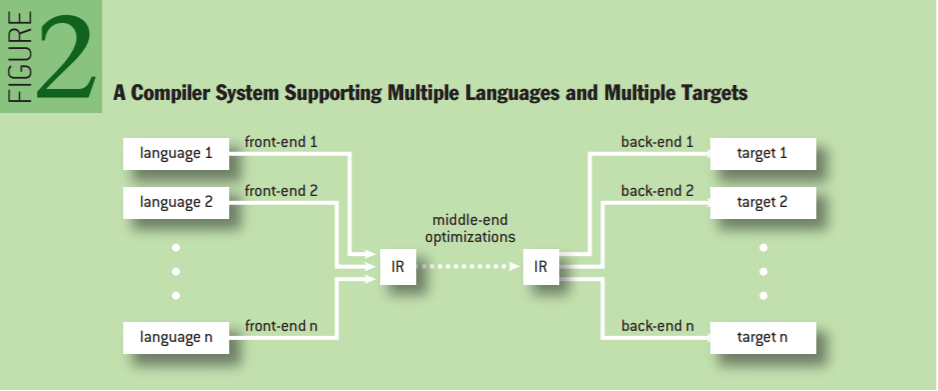
华为方舟编译器的MapleIR在设计的时候,主要是基于下面三点:
1、IR存在于三种不同的格式中:Binary,主要是用来做分发,或者是真正要执行的时候,主要考虑到效率;Text,因为程序员还是要看一看中间到底发生了什么变化,要有可读性;有一个In-memory的过程,在整个的编译过程中,可以看到如何组织中间语言在内存的存储。
2、分层设计,整个Maple借鉴了一些Open64的经验,形成分层的设计,按需来选择不同层次。高层的语言可以比较快速的回到源代码,对实现一些接近原语言的优化会比较方便,中间的结构也能够更加的精简,假如说以后拿这个来分发的时候,分发的格式也会比较小。
3、提供编译器优化重用能力,当引入了新的语言,就是说我们有了新的前端之后,能够尽量的改得少一点,话外之意?
高级语言为了方便程序员开发大型程序有很多的特性,比如类的继承,对于JAVA这样的单继承语言MIR会对这个结构产生一个唯一的序,然后每个类都会有一个类似的表来表明继承关系。有意思的来了,并不是所有语言都是单继承,比如C++就是多继承,不知道后面如何表示和统一,很期待后面的开源。

前面我们提到过JAVA的一个重要特性——反射,方舟编译器反射的内部表示的数据结构和art内部实现是完全不一样的,是华为自己定义出来的,主要是基于一些性能开销的考虑。在ClASSMETADATA中前面相当于是一个object的头,然后是shadow和monitor还有一些itab、vtba、gctib等。这个class里面有自己的field和Method,它现在的定义就是一个数组,Class这边是一个object,目前保存的其实不是一个object,在运行的时候,这部分会自己malloc出来一个object,然后会把这部分数据拷过去,这样就符合Java的语义了。我们定义完之后,需要重新实现重写所有用到上述数据的函数实现,需要付出另外一个代价,重写上面所有的Java函数,保持Java的接口不变,但是里面的实现是完全不能重用的。

对于程序运行来说,内存是一种宝贵的资源,使用的时候需要申请,不需要的时候需要释放,对于大型程序来说一个自动的内存管理机制是很有必要的。自动内存管理通常有两种垃圾回收策略:一种是引用追踪垃圾回收(TracingGarbageCollection,TracingGC),另一种是基于引用计数(ReferenceCounting,RC)垃圾回收,Android的开发语音是JAVA,JAVA采用的是GC的方式。JAVA的GC追踪过程回依赖整个系统中多线程的间歇同步和停顿,这种停顿在用户的感知上就是卡顿(GC只是引起卡顿的其中一个原因并非全部),想要彻底的解决卡顿的问题GC是必须要考虑的问题。华为方舟编译器将RC引入了进来,RC的方式是在函数返回时或异常退出时进行标记,这些操作会带来额外的开销,华为是想通过编译器优化将RC开销降低。
RC并不是一种落后的内存回收机制,广受好评的苹果swift就采用的RC回收机制,在用户体验非常重要的客户端RC其实很适合,但是JAVA实现RC并不是很好弄,他还有庞大的旧JAVA库。方舟编译器引入RC机制的目的为了解决GC造成的卡顿问题,RC的机制最大的问题在于可能产生循环引用,方舟编译器的应对方法是:
1、程序员标记(目前还没有开放给第三方);
2、引入一个环模式匹配的算法,在Runtime里会收集环在程序过程中的信息记录到手机上,然后给三方应有使用,这是一个学习的过程,学习完下次运行时就会快速知道如何避免这些环;
3、GC兜底确保环能正确的解掉。
对于这个解决方案,第二步的自学习有创新性而且是很关键的,内存管理中比卡顿更重要的是正确性,回收内存一旦出问题整个程序可能都会出错。如何保证自学习解环的正确性呢?根据华为方舟编译器架构师的说法:
自学习可以理解成一种profiling的技术,它只会帮你指导,比如你在前面一遍走过的时候,我现在这边肯定一个环。第二次假如我走到这边,如果我还是碰到这么一个环,你再重新释放这部分肯定没有问题。
但自学习有一个问题,就像其他profiling的问题是一样的,因为profiling肯定不可能跑全。比如我这次跑和下次跑整个环境或者跑的路径都不太一样,有可能你前一个跑一遍之后,你学了很多的pattern,然后什么都搞定了。第二下次跑的时候,一个pattern都没跑到,那你学习就算白学了,但它的正确性是没有问题的。
所以说方舟编译器还是需要GC兜底的,方舟编译器并没有抛弃GC,而是采用了RC为主GC兜底的方式。当内存阈值,或者程序员调动的时候使用GC来回收内存,根据在首场开源技术沙龙上方舟编译器架构师的说法触发GC的几率大概为5%,这样确实可以大大提高流畅性,目的基本达到了。
虽然我学过JAVA语言,学过编译原理,但是并没有实际的做过编译器项目,其实国内懂编译器的并不多,对于方舟编译器的解释可能有部分不到位,请谅解。对于方舟编译器我还是乐见其成的。对于方舟编译器会不会使得Android的碎片化问题更严重,华为的人也给出一个回复:
曾邀请过Google参与这个社区,开源前已经跟Google讨论过很多次,但是美国禁令事件打断了双方的沟通。
附录:
FredChow的《TheChallengeofCross-languageInteroperability》:编译器简介:
方舟编译器开源地址:



