作者:monychen
1.背景最近AI圈内乃至整个科技圈最爆的新闻莫过于OpenAI的Sora了,感觉热度甚至远超之前ChatGPT发布时的热度。OpenAI也是放出了Sora的技术报告(有一定的信息量,也留下了大量的想象空间)。
技术报告传送门:
今天就来尝试聊一下Sora的前世今生,欢迎交流讨论批评指正!
自编码器(Autoencoder):压缩大于生成
自编码器由编码器和解码器两个部分构成
编码器负责学习输入到编码的映射,将高维输入(例如图片)转化为低维编码
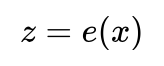
解码器则学习编码到输出的映射,将这些低维编码还原为高维输出(例如重构的图片)
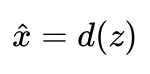
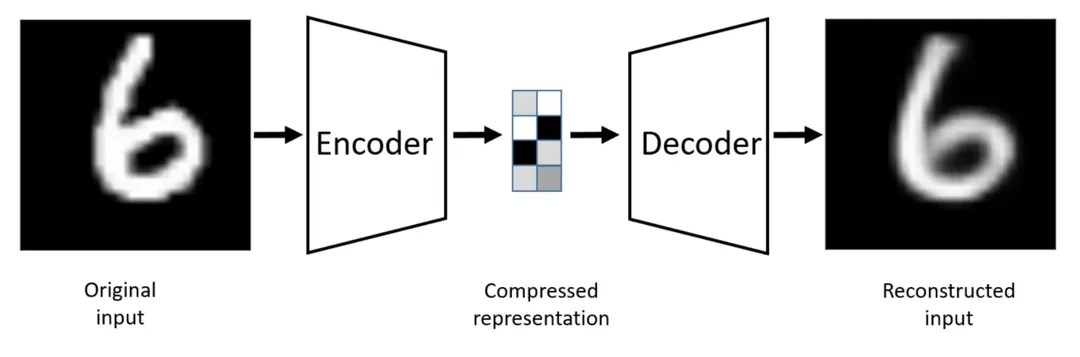
我们希望压缩前和还原后的向量尽可能相似(比如让它们的平均平方误差MSE尽可能小)
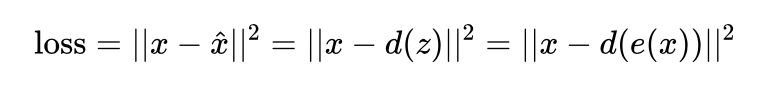
这样就能让神经网络学会使用低维编码表征原始的高维向量(例如图片)。
那有了自编码器能够做生成吗,答案是可以的,只要留下解码器,我随便喂入一个低维编码,不就能够得到一个生成的高维向量了(例如图片)。(当然,这里可能生成一起奇奇怪怪的东西,因为这里对低维向量没有做出约束,自编码器通过将图片转化为数值编码再还原回图片的过程,可能导致对训练数据过拟合。结果就是,对于未见过的低维编码,解码器重构的图片质量通常不佳。因此自编码器更多用于数据压缩。)
变分自编码器(VariationalAutoencoders):迈向更鲁棒地生成自编码器不擅长图片生成是因为过拟合,那如果能够解决过拟合问题,不就能拿来生成图片了!
变分自编码器做的就是这么一件事:既然自编码器将图片编码为确定性的数值编码会导致过拟合,变分自编码器就将图片编码为一个具有随机性的概率分布,比如标准正态分布。这样当模型训练好后,我们只要给解码器喂入采样自标准正态分布的低维向量,就能够生成较为“真实”的图片了。
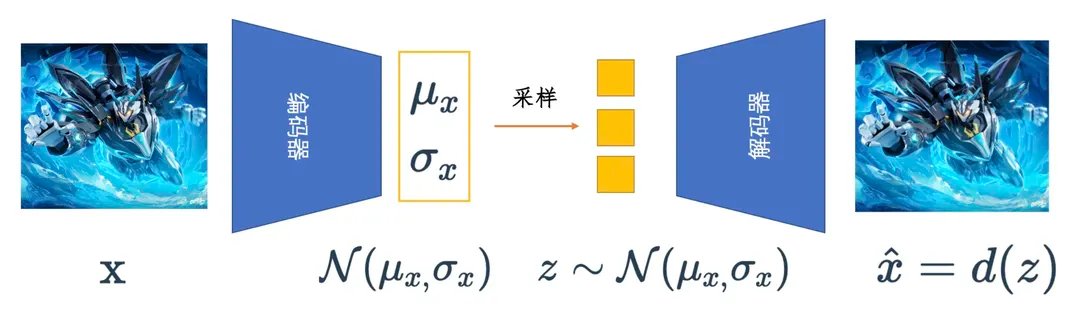
因此,变分自编码器除了希望编码前和解码后的样本尽可能相似(MSE尽可能小),还希望用于解码的数据服从标准正态分布,也就是低维编码的分布和标准正态分布的KL散度尽可能小,损失函数加上这么一项约束。
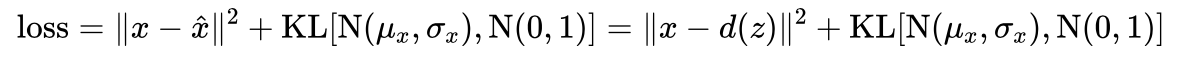
变分自编码器减轻了自编码器过拟合的问题,也确实能够用来做图片的生成了,但是大家会发现用它生成图片通常会比较模糊。可以这样想一下,变分自编码器的编码器和解码器都是一个神经网络,编码过程和解码过程都是一步就到位了,一步到位可能带来的问题就是建模概率分布的能力有限/或者说能够对图片生成过程施加的约束是有限的/或者说“可控性”是比较低的。
去噪扩散概率模型(DDPM):慢工出细活既然变分自编码器一步到位的编解码方式可能导致生成图片的效果不太理想,DDPM就考虑拆成多步来做,它将编码过程和解码过程分解为多步:
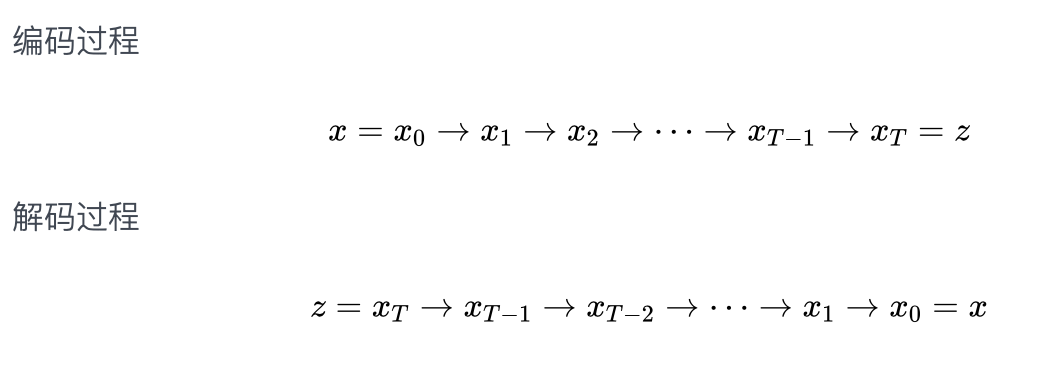
因此,所谓的扩散模型由两个阶段构成
前向扩散过程,比如给定一张照片,不断(也就是多步)往图片上添加噪声,直到最后这样图片看上去什么都不是(就是个纯噪声)
反向去噪过程,给定噪声,不断执行去噪的这一操作,最终得到一张“真实好看”的照片
下图中从右往左就是前向扩散的过程,从左往右就是反向去噪的过程
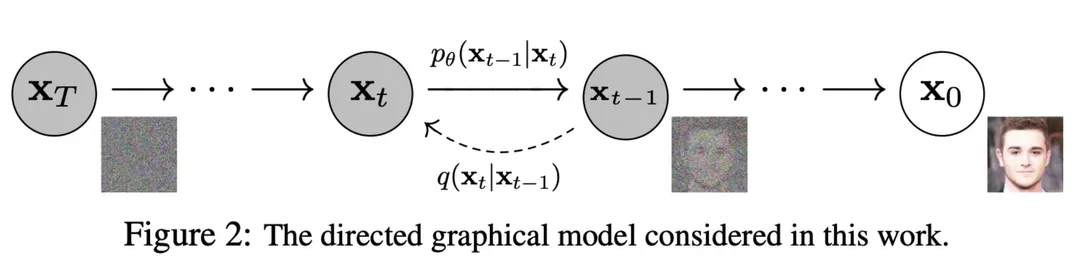
可以看到每一步的下标有一个,的范围从到,代表从数据集中采样出一张图片,前向过程在每一步从高斯分布中采样出噪声叠加到时刻的图像上,当足够大时,最终会得到一个各向同性的高斯分布(球形高斯分布,也就是各个方向方差都一样的多维高斯分布)。
DDPM通过多步迭代生成得到图片缓解了变分自编码器生成图片模糊的问题,但是由于多步去噪过程需要对同一尺寸的图片数据进行操作,也就导致了越大的图片需要的计算资源越多(原来只要处理一次,现在有几步就要处理几次)。
DDPM细节推导(选读)下面从数学一点的角度对DDPM进行介绍,不感兴趣的同学可以直接跳过
假设原始数据的分布为,从数据集中拿出一张图片就类似于从原始数据分布中进行采样,进一步可以定义第步的前向扩散过程为
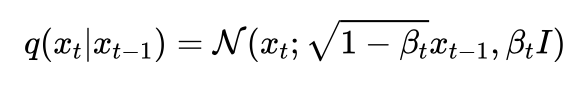


综上,算法的训练流程可以表示为

算法流程
随机从数据集中采样图片
随机采样一个步数
从高斯分布中采样一个噪声并通过niceproperty得到步后含噪的图片
神经网络根据预测噪声,计算误差,反向传播
PS:在原论文中作者把方差给固定住了,仅学习均值部分来实现去噪的效果(当然,后续也有改进论文提出把方差也一起拿来学习)。

对于时间步长t,可以将其转化为timeembedding(比如类似positionembedding的做法),然后叠加到(U-net的各层)图片上。
模型结构也确定了,怎么训练也知道了,那么训练完后该如何生成图片呢?图片的生成过程也称为采样的过程,流程如下

反向去噪过程:从高斯分布中采样一个噪声,从时刻开始,每次通过训练好的神经网络预测噪声,然后得到略微去噪后的图片,再代入神经网络预测噪声,不断迭代,最终得到第0步的图片。
潜在扩散模型(LDM):借助VAE来降本增效
下面关于LDM的一些细节介绍,不感兴趣的同学可以直接跳过。
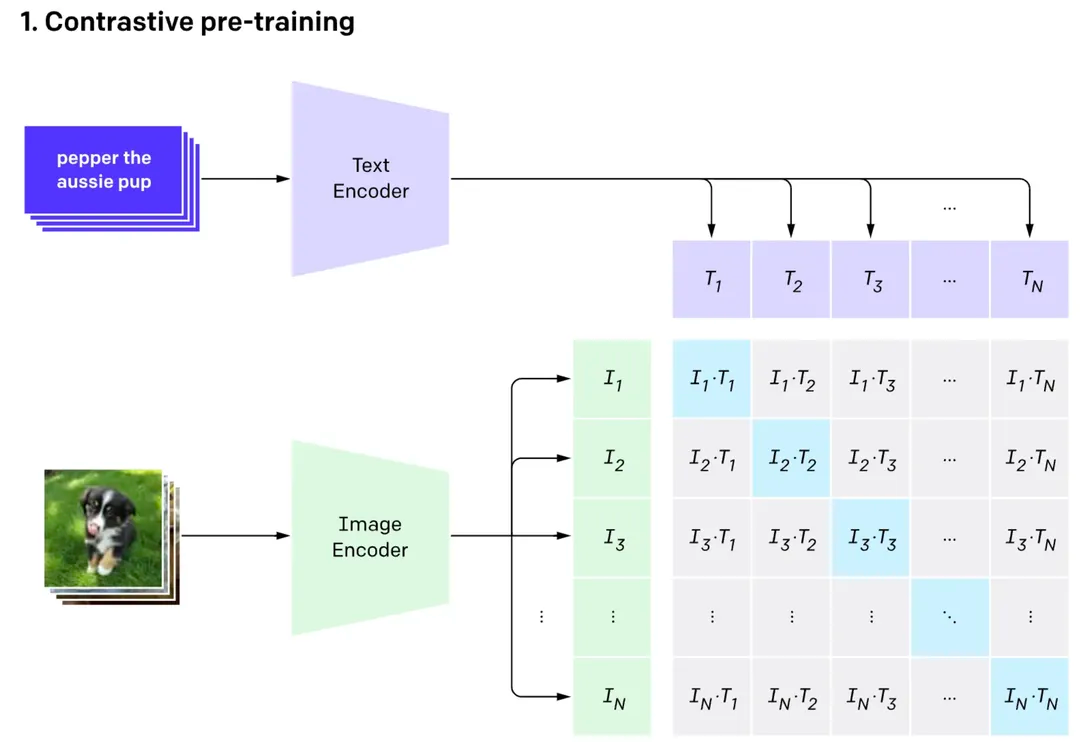
理解了latent的含义后,接下来再考虑下如何根据文本来生成图片呢?既然要接收文本,那就需要给模型安排上文本编码器(textencoder),把文本转化为模型能够理解的东西。StableDiffusion采用了CLIP的文本编码器,它的输入是一段文本,输出是77个token的embeddings向量,每个向量的维度为768(可以理解为一段话最多保留77个字(或词),每个字(或词)用768维的向量表示)。

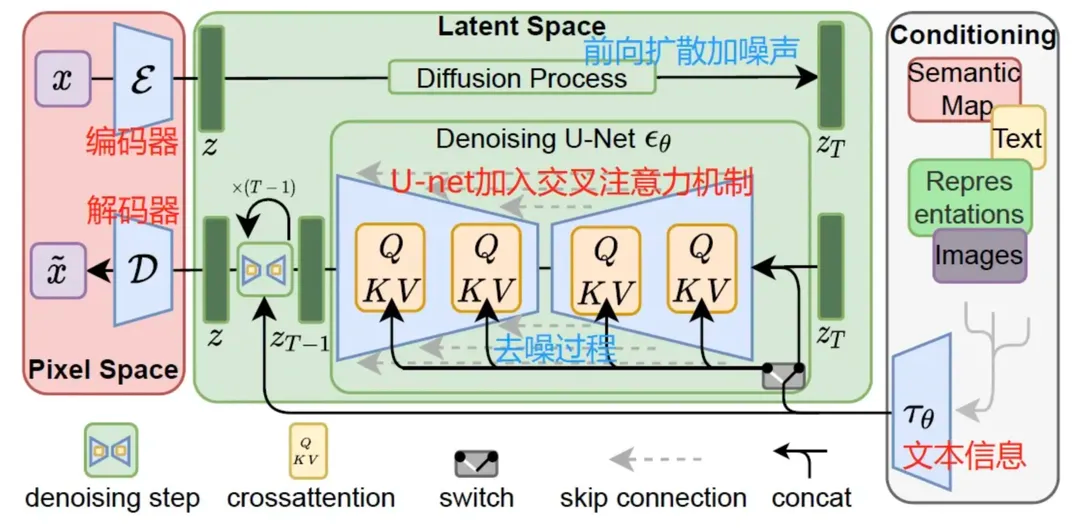
得到文本的表示后,就需要考虑如何在原来的U-net里叠加上文本的信息呢?原来的U-net的输入由两部分组成
加噪后的图片
时间步长(t)
现在则是由三部分组成
加噪后的图片
时间步长(t)
文本的tokenembedding
为了能够充分利用文本的信息,让模型按照文本的意思来绘画,StableDiffusion提出了一种文本和图片之间的交叉注意力机制,具体的

其中,来自于图像侧,和来自于文本侧;可以理解为计算图像和文本的相似度,然后根据这个相似度作为系数对文本进行加权。在前面U-net的基础上,每个resnet之后接上这样一个注意力机制就得到了注入文本信息的U-net的结构了。
然后就可以愉快地像之前的DDPM一样,预测噪声,最小化MSE,学习模型了!
最后再来一张整体的结构图总结一下
LDM的扩散模型使用了U-net这一网络结构,但这个结构会是最佳的吗?
参考其他领域或者任务的经验,比如去年火了一整年的大语言模型、多模态大模型绝大部分用的都是Transformer结构,相比于U-net,Transformer结构的Scaling能力(模型参数量越大,性能越强)更受大家认可。因此,DiT其实就是把LDM中的U-net替换成了Transformer,并在VisionTransformer模块的基础上做了略微的修改使得在图片生成过程能够接受一些额外的信息,比如时间步,标签。
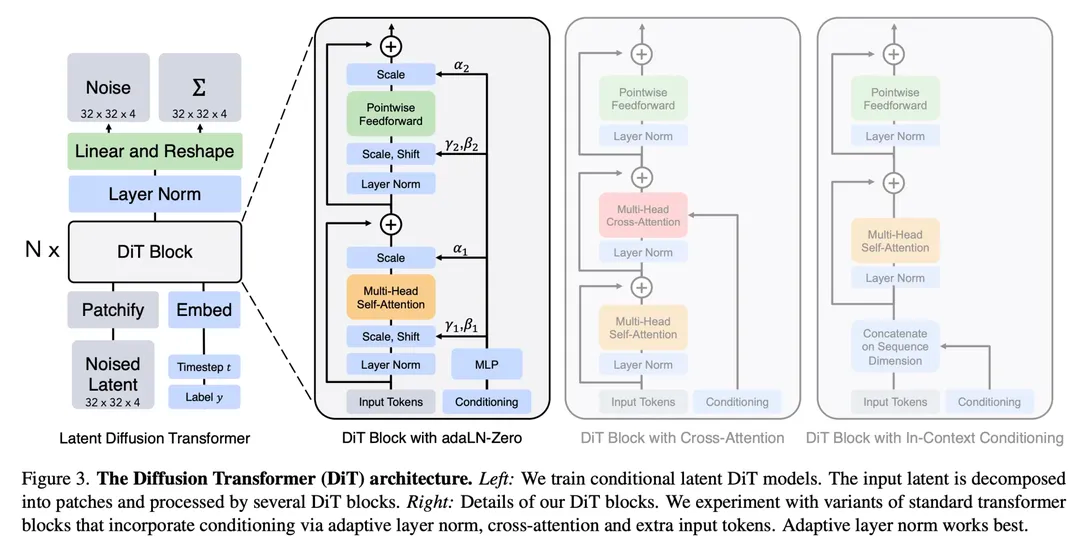
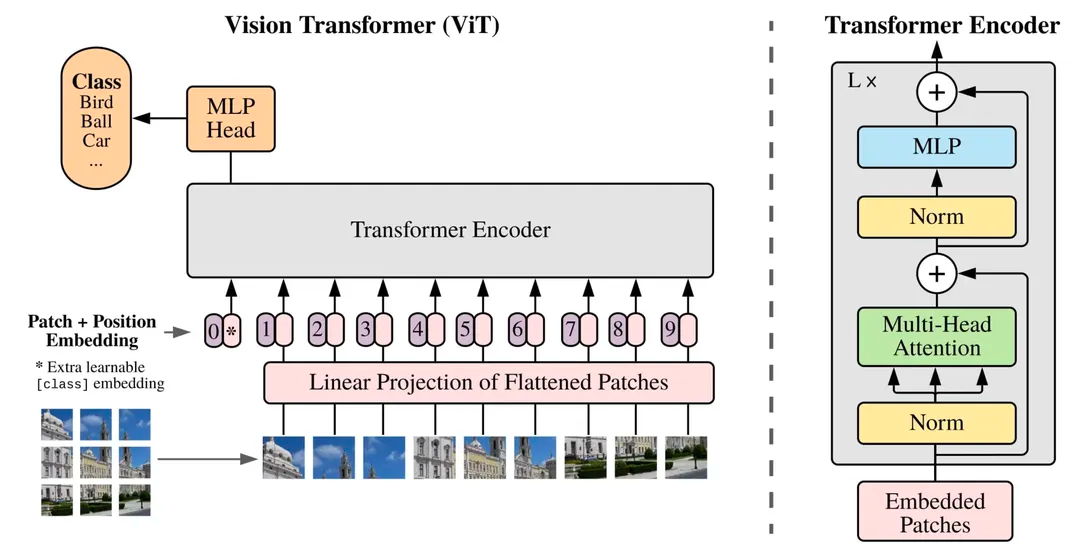
既然要用Transformer来替换U-net,我们需要了解一下Transformer如何处理图片数据的呢?经典之作当然是VisionTransformer(ViT)了,它的主要思想就是将图片分割为固定大小的图像块(imagepatch/token),对于每个图像块进行线性变换并添加位置信息,然后将得到的向量序列送入一个标准的Transformer编码器。

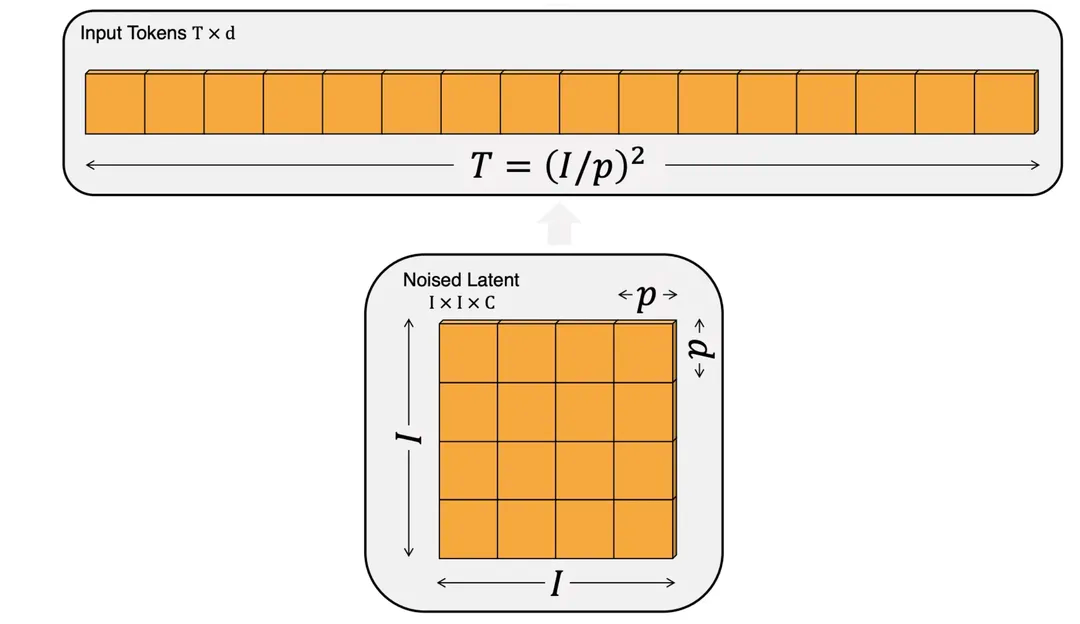
先抛出我的观点:Sora就是改进的DiT。
而DiT本质上是VAE编码器+ViT+DDPM+VAE解码器;从OpenAI的技术报告体现出来的创新点我认为主要有两个方面:
改进VAE-时空编码器
改进DiT-不限制分辨率和时长
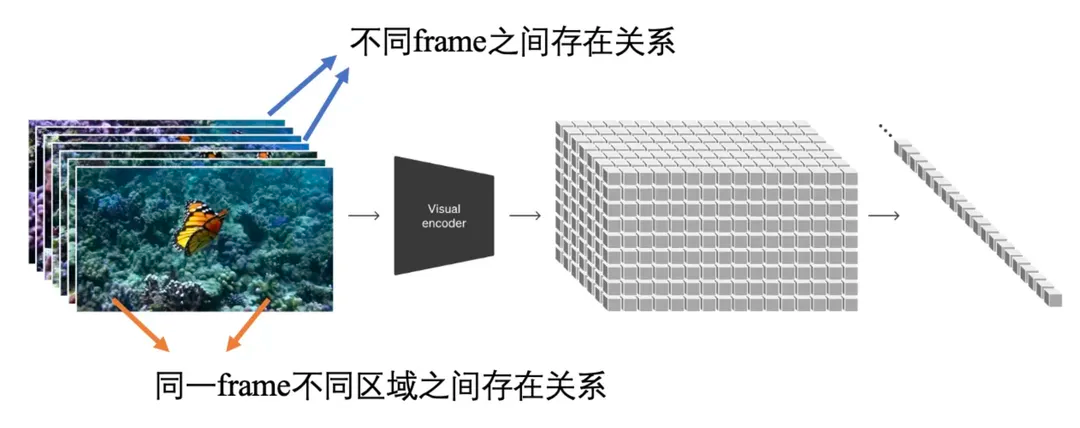
对应的就是Sora技术报告中的Videocompressionnetwork
技术报告中没有提及具体的做法,但是可以看出这里显然是在VAE编码器上考虑了时空建模,对于解码器的设计没有相关介绍(可能也考虑了时空建模,也可能不做改动)。
改进DiT:适配任意分辨率和时长网上的很多分享都在传Sora能适配任意分辨率和时长是参考了NaViT这篇文章的做法,其实并非如此,VisionTransformer(ViT)本身就能够处理任意分辨率(不同分辨率就是相当于不同长度的图片块序列,不就类似你给大语言模型提供不同长度的输入一个意思)!NaViT只是提供了一种高效训练的方法。

一种可行的做法就是从位置编码的角度入手,比如对于输入Transformer的图片块,我们可以在patchembedding上叠加上时间、空间上的位置信息。
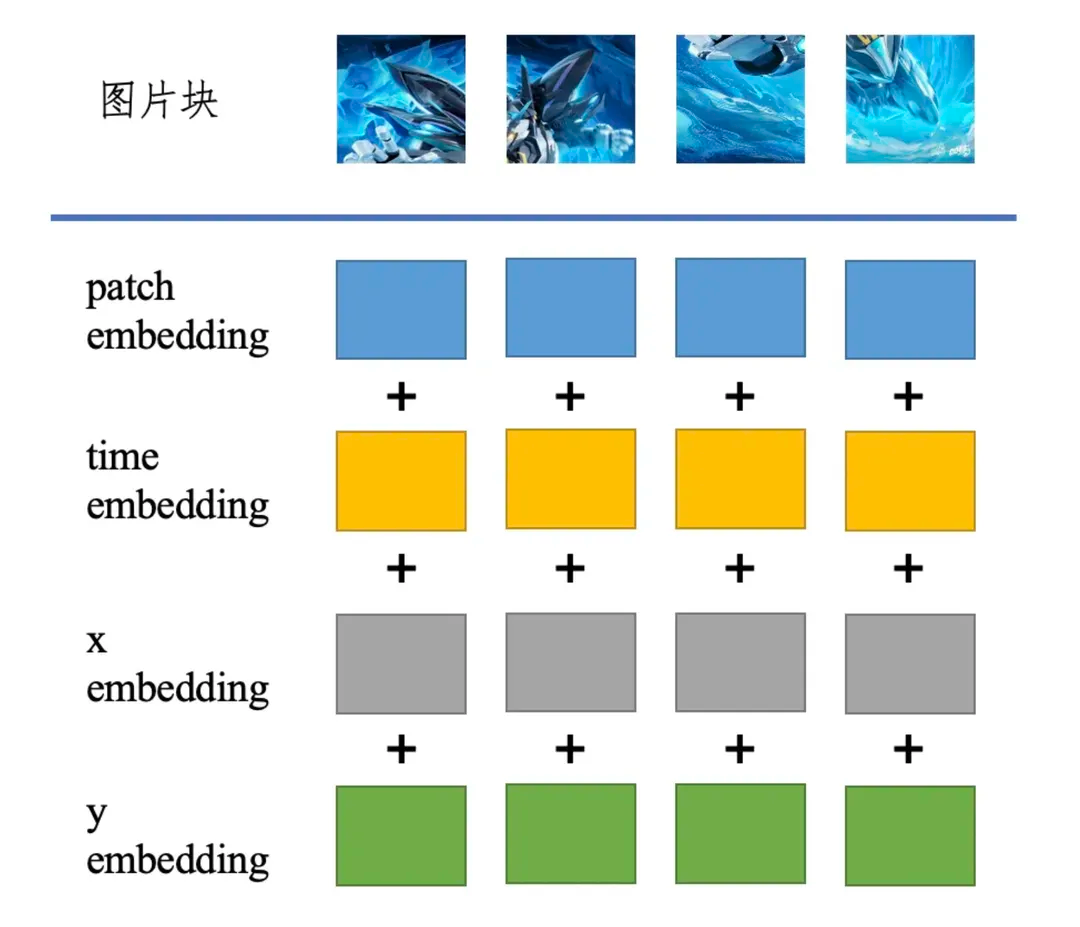
在数据层面上,OpenAI也给出了两点很有参考价值的方法
那么DALL·E3是如何做re-captioning的呢?(选读)
既然是生成文本,自然就是类GPT的语言模型,做的就是下一个词预测;考虑到生成的文本是图像的描述,因此需要基于图像这个条件,也就是条件生成,要把image放进去
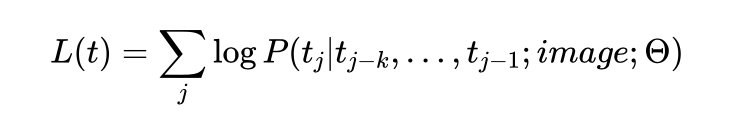
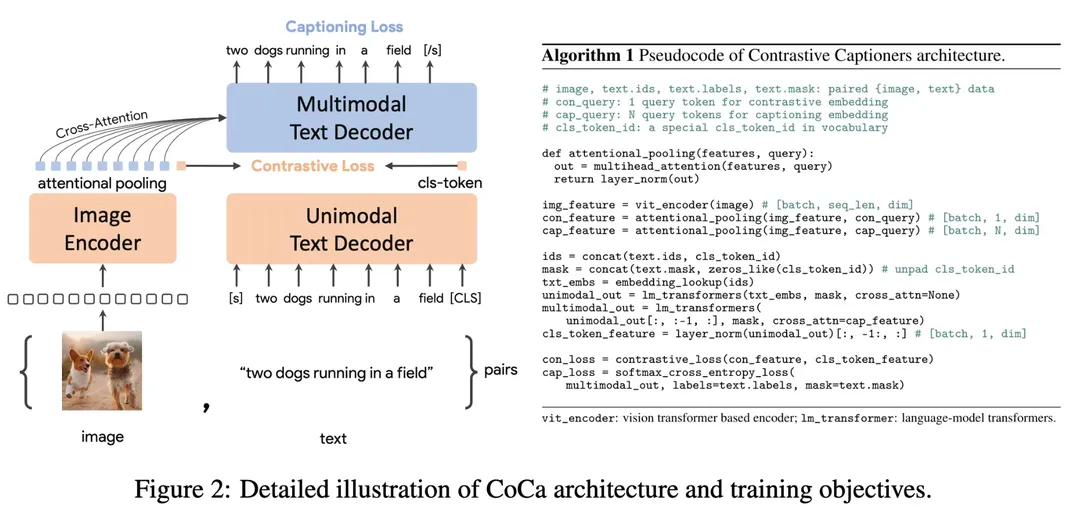
那么图像以什么形式放进去呢?简单点,就用CLIP来编码图像,然后把图像embedding放进去就ok了。那这样一个图像打标模型怎么训练呢?用的就是CoCa的方法,也就是同时考虑对比损失和LM损失
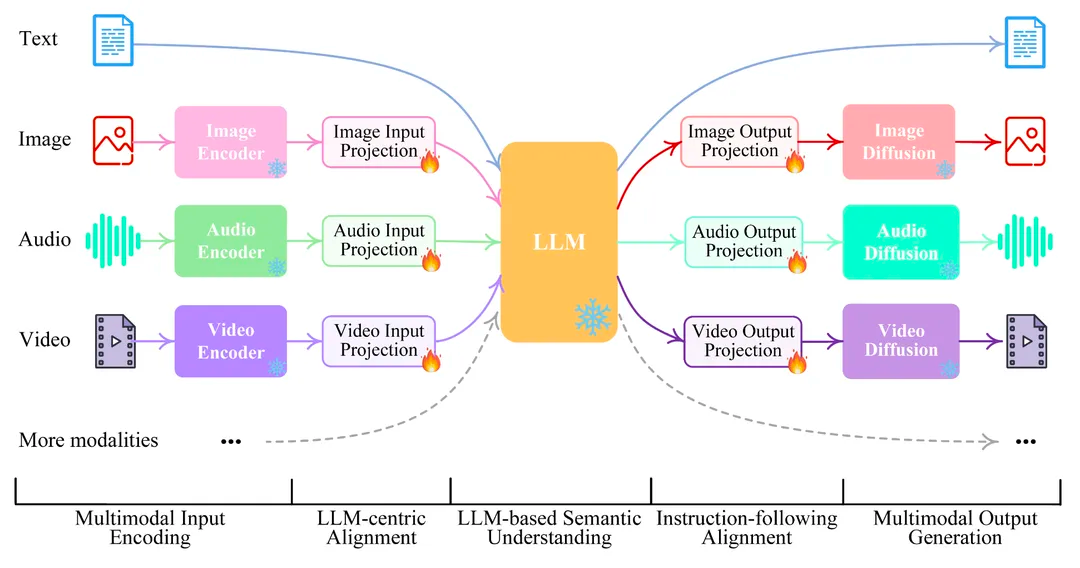
比如可以参考NExT-GPT的一个结构图
相信2024年同样会是AI领域突飞猛进的一年,期待更多精彩的工作。
【参考资料】
Autoencoders,
Auto-EncodingVariationalBayes,
DenoisingDiffusionProbabilisticModels,
High-ResolutionImageSynthesiswithLatentDiffusionModels,
ScalableDiffusionModelswithTransformers,
AnImageisWorth16x16Words:TransformersforImageRecognitionatScale,
Sora,
VideoLDM,
NaViT,
CoCa,
NExT-GPT,



